

Choosing the Right Graph
When to Use a Labeled Property Graph and When to Use an RDF Ontology-Based Knowledge Graph

Introduction
Since roughly 2012, the knowledge graph category has collapsed, derived from two quite different intellectual traditions into a single marketing category. The first — the Resource Description Framework (RDF) and its associated Web Ontology Language (OWL) — descends from formal logic, knowledge representation, library science and Tim Berners-Lee’s Semantic Web.1 The second — the labeled property graph (LPG) used by Neo4j, Apache TinkerPop/Gremlin, and most contemporary graph databases — descends from graph theory, object-oriented databases and the operational demands of connected-data applications such as social networks, fraud detection and recommendation engines.2
Both are graphs, and both are routinely used to build what vendors call “knowledge graphs,” yet the data models, semantics, query languages, governance assumptions and engineering economics differ enough that picking the wrong one is a costly architectural mistake. This essay reconstructs the intellectual history of each model, compares them technically and offer s a decision framework — including the increasingly important hybrid case, which the arrival of RDF 1.2 in 2026 has materially reshaped.
The History of RDF Knowledge Graphs
Deep Roots
The conceptual ancestor of every modern ontology language is the semantic network. The notion that meaning can be modeled as a graph of concepts joined by labeled edges entered cognitive science and AI through M. Ross Quillian’s 1968 paper “Semantic Memory,” published as a chapter in Marvin Minsky’s edited volume Semantic Information Processing at MIT Press.3
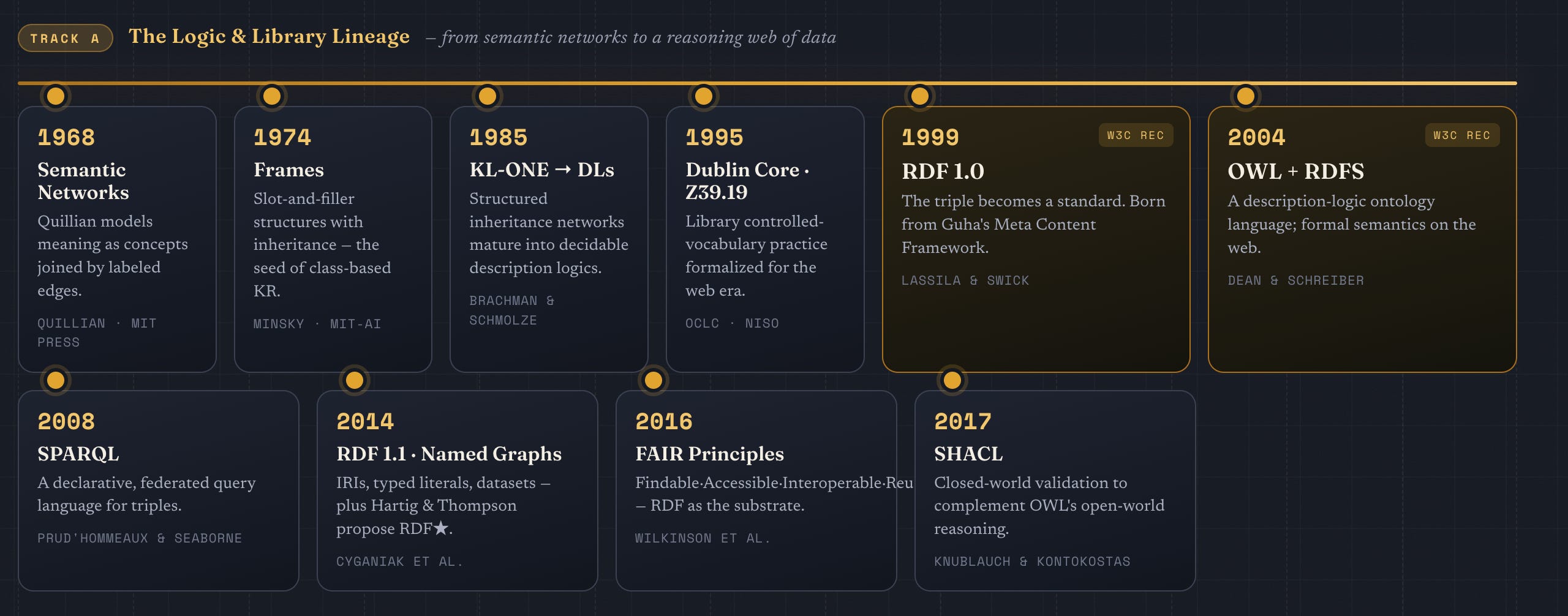
Minsky himself, in his 1974 MIT-AI memo A Framework for Representing Knowledge (reprinted in Winston’s The Psychology of Computer Vision the following year), introduced frames— slot-and-filler structures with defaults and inheritance — which became the template for class-based knowledge representation.4 The line ran from frames to KL-ONE, Ronald J. Brachman’s structured inheritance network developed from 1977 onward and canonically described by Brachman and Schmolze in Cognitive Science in 1985.5 KL-ONE’s formal descendants are the description logics (DLs), which provide decidable fragments of first-order logic with well-understood complexity bounds and serve as the mathematical foundation of OWL.6
Running alongside this AI lineage is an older librarianship tradition of metadata, controlled vocabularies, thesauri and authority files. The Dublin Core Metadata Element Set originated at the OCLC/NCSA Metadata Workshop in Dublin, Ohio in March 1995, was standardized through IETF RFC 5013, ANSI/NISO Z39.85 and ultimately ISO 15836.7 ANSI/NISO Z39.19, first issued in 1974 and substantially rewritten as Z39.19-2005 (R2010), gave the United States its definitive Guidelines for the Construction, Format, and Management of Monolingual Controlled Vocabularies, codifying decades of thesaurus practice.8 Library cataloging standards such as FRBR, Dublin Core, Linked Data authority sources, MARC and RDA supplied the practical experience of running shared vocabularies across institutions for many decades — experience that the Semantic Web community would inherit and extend through W3C SKOS, which became a W3C Recommendation on 18 August 2009 under editors Alistair Miles and Sean Bechhofer.9
From Meta Content Framework to RDF (1995–1999)
The direct technical precursor of RDF was the Meta Content Framework (MCF), developed by Ramanathan V. Guha at Apple’s Advanced Technology Group between 1995 and 1997, rooted explicitly in CycL, which Guha had co-designed at Cycorp, KRL and KIF.10 When Apple cancelled the project in 1997, Guha moved to Netscape, where, together with Tim Bray, co-editor of XML, he produced an XML serialization of MCF and submitted it to the W3C in June 1997.11 This submission — combined with W3C’s earlier Platform for Internet Content Selection (PICS), Dublin Core and contributions from IBM, Microsoft, Nokia, Reuters, SoftQuad and the University of Michigan — became the Resource Description Framework (RDF) Model and Syntax Specification, edited by Ora Lassila and Ralph Swick, which the W3C published as a Recommendation on 22 February 1999.12
Berners-Lee’s Semantic Web vision (1998–2001)
Tim Berners-Lee had set the strategic context one year earlier in his September 1998 design note Semantic Web Road map, which described “a web of data, in some ways like a global database” and laid out the planned layering of RDF, schemas, logic and proof.13 This vision reached a much wider audience through the May 2001 Scientific American article “The Semantic Web,” co-authored by Berners-Lee, James Hendler and Ora Lassila, whose Aunt-Lucy-and-the-medical-agent thought experiment defined the popular imagination of machine-readable web data for the next two decades.14
RDF Schema, OWL, SPARQL and the Standard Stack (2004–2014)
The W3C reorganized its Metadata Activity into a Semantic Web Activity in 2001 and chartered two working groups: the RDF Core Working Group to formalize RDF’s semantics, and the Web Ontology Working Group to design an ontology language.15 The result, on February 10th, 2004, was a coordinated six-part RDF revision that included Concepts and Abstract Syntax, Semantics, Schema, Syntax, Vocabulary, Test Cases, together with the OWL Web Ontology Language Recommendation, whose OWL DL profile was grounded in the SHIQ description logic and explicitly descended from DAML+OIL.16
A standard query language followed. SPARQL Query Language for RDF, edited by Eric Prud’hommeaux and Andy Seaborne, became a W3C Recommendation on 15 January 2008, and the eleven-document SPARQL 1.1 family — adding aggregates, subqueries, property paths, federation via `SERVICE`, update and entailment regimes — was issued on 21 Marh 201317. OWL 2 became a Recommendation on 27 October 2009 (Second Edition on 11 December 2012), formalizing the EL, QL and RL profiles tuned to different reasoning workloads.18
Two further developments matured the stack. First, RDF 1.1, published as a suite of W3C Recommendations on 25 February 2014, replaced URIs with IRIs, made all literals typed, and — most importantly — formalized the RDF Dataset concept of a default graph plus zero or more named graphs, building on the influential 2005 paper “Named Graphs, Provenance and Trust” by Carroll, Bizer, Hayes, and Stickler at WWW 2005.19 Second, the Shapes Constraint Language (SHACL), edited by Holger Knublauch and Dimitris Kontokostas, became a W3C Recommendation on 20 July 2017, providing a closed-world validation language that complements OWL’s open-world reasoning.20 Provenance was standardized through PROV, whose OWL2 ontology PROV-O (edited by Lebo, Sahoo, and McGuinness) reached Recommendation on 30 April 2013.21
Linked data, FAIR and Vocabularies
The Semantic Web’s center of gravity shifted in the late 2000s from grand reasoning to practical linked data publishing, as initialized by Berners-Lee’s four “linked data” rules and the Linked Open Data cloud , which popularized URI dereferencing and vocabulary reuse. Communities converged on a small set of dominant vocabularies, mainly Dublin Core for bibliographic metadata, Friend of a Friend (FOAF) for people and social networks, SKOS for thesauri and taxonomies, PROV-O for provenance and schema.org for web publishing, under the leadership, once again, of R. V. Guha.22
The FAIR Guiding Principles for Scientific Data Management and Stewardship — the FAIR acronym translating to Findable, Accessible, Interoperable, Reusable — was published by Wilkinson et al. in Scientific Data on 15 March 2016 (DOI 10.1038/sdata.2016.18) and rapidly became the de facto policy framework for European and life-sciences research data, with RDF and ontology-based identifiers as their canonical implementation strata.23
RDF-Star and the Road to RDF 1.2 (2014–2026)
For two decades, RDF had an awkward limitation compared to property graphs in that a triple couldn’t hold information about itself. A triple states a bare fact — Beatles recorded AbbeyRoad — but gives you nowhere to record who said so, how confident they were or when it was true. Practitioners fell back on three workarounds.
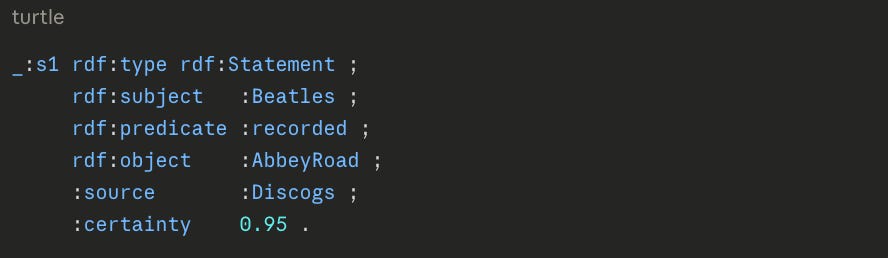
Reification creates a separate statement node that points back to the original subject, predicate and object, then attaches metadata to that node — effective, but it costs four extra triples per fact and only describes the statement without asserting that it’s true. An intermediate node invents a node to stand for the relationship itself, so you can hang metadata off it — but this adds a node that represents nothing real except a place to store data. A named graph, which is a labeled bundle of triples meant for tracking where facts came from, gets repurposed by stuffing a single fact into its own bundle just to get a label to annotate. All three solve the same problem, since the fact can’t carry metadata itself, the solution being to build an indirect container to hold it.
The decisive proposal to fix this came from Olaf Hartig and Bryan Thompson, whose June 2014 paper Foundations of an Alternative Approach to Reification in RDF (arXiv:1406.3399) introduced RDF* which later became known as RDF-star and its companion query extension SPARQL*.24 An RDF-DEV Community Group consolidated the design into a Final Report in 2021, and the W3C chartered the RDF-star Working Group on 29 August 2022 to standardize it; that group rechartered itself on 1 May 2025 as the broader-scoped RDF & SPARQL Working Group.25
The standardized result is RDF 1.2, whose central document, RDF 1.2 Concepts and Abstract Data Model, advanced to a W3C Candidate Recommendation Snapshot dated 7 April 2026, alongside RDF 1.2 Semantics. The W3C call for implementations set the earliest possible Recommendation date at 5 May 2026.26 The published design differs from the 2014–2021 RDF-star drafts, instrumental for any architectural comparison with property graphs.
RDF 1.2 introduces a triple term, an RDF triple used as the object of another triple, added as a fourth kind of term alongside IRIs, blank nodes, and literals.27 It abandons the earlier “quoted triple” terminology and the `<< s p o >>`-in-subject-position freedom: a triple term may appear only in object position, never as subject o graph name28 Statement-level annotation is now built around a new property, rdf:reifies, and a new class, rdfs:Proposition; statement-level metadata is expressed through a reifying triple of the form ?reifier rdf:reifies ?pleTerm. It introduces a reifier — any IRI or blank node — that denotes the proposition expressed by the triple term, and metadata is attached to that reifier, rather than to the triple term itself.
Two refinements resolve the long-running RDF-star ambiguities. First, a triple term is never self-referential - you cannot “refer” in one term to another triple. Using a triple as an object asserts nothing and a proposition is asserted only if the same triple also appears as a top-level triple in the graph.29 Second, triple terms are transparent, meaning referentially open— the terms inside denote exactly what they denote outside — settling the “referential opacity” debates of the RDF-star era.30 The RDF 1.2 also adds a second, unrelated capability that closes an internationalization gap. Directional language-tagged strings, a new datatype rdf:dirLangString,whose literals carry a base direction—left to right (ltr) or right to left (rtl) —so that mixed-script text — such as Arabic or Hebrew interleaved with Latin — renders correctly..31
RDF knowledge graphs descend from two converging traditions—the AI lineage of semantic networks, frames and description logics (Quillian, Minsky, Brachman's KL-ONE) that became the formal basis of OWL, and the older librarianship tradition of controlled vocabularies and metadata standards (Dublin Core, ANSI/NISO Z39.19, FRBR, SKOS). These streams merged in the late 1990s when Guha's Meta Content Framework was serialized in XML and standardized by the W3C as RDF in 1999, after which Berners-Lee's Semantic Web vision drove a maturing stack of standards — RDF Schema, OWL, SPARQL, named graphs, SHACL, and PROV — alongside the practical turn toward linked data and FAIR principles. The long-standing inability of a triple to describe itself was finally resolved through RDF-star (Hartig and Thompson, 2014) and its standardization as RDF 1.2, which reached Candidate Recommendation in April 2026.
The History of Property Graphs and Labeled Property Graphs
Mathematical and Database Antecedents
Graph theory as a formal discipline began with Leonhard Euler’s 1736 solution to the Königsberg bridges problem, the conventional birth date of the field. Graph databases as a distinct database category emerged in the 1980s and early 1990s alongside object-oriented databases, with models such as GOOD, GMOD, G-Log, and Gram representing both schema and instance as labeled digraphs. Renzo Angles and Claudio Gutierrez’s Survey of Graph Database Models in ACM Computing Surveys (February 2008) is the canonical historical treatment of that first wave, which faded in the late 1990s under pressure from semistructured and XML approaches before being revived in the late 2000s.32

Neo4j and the Term “Graph Database”
The modern property graph era begins with a napkin sketch. In 2000, on a flight to Mumbai, Emil Eifrem — then working in Swedish enterprise software at Windh AB — sketched what would become the labeled property graph model with his colleagues Johan Svensson and Peter Neubauer. As Eifrem later told TechCrunch, “We conceived the idea for the first property graph database during a flight to Mumbai in 2000. We sketched it on a napkin — one that I wish I still had but, alas, has since disappeared.“33
Prototypes circulated within Windh from roughly 2000 onward, and Neo Technology’s own corporate timeline records the first 24×7 production Neo4j deployment in 2003. The trio formally founded Neo Technology, later renamed Neo4j, Inc. in 2007, and open-sourced the database under the GPL, releasing Neo4j 1.0 in 2010.34 Eifrem is generally credited with coining the term “graph database” in its modern incarnation. Neo4j popularized the property graph model, in which both nodes and relationships carry labels and arbitrary key–value properties, and relationships are first-class entities with their own identity and direction.35
Neo4j relocated its headquarters from Sweden to San Mateo, California in 2011 specifically to raise venture capital — a strategy that ultimately delivered roughly $550 million in funding, including a landmark $325 million Series F in June 2021, led by Eurazeo and Google Ventures.36
The defining engineering claim of native graph databases such as Neo4j is index-free adjacency where relationships are stored as direct physical pointers between node records rather than as rows joined through indexes, so a one-hop traversal is O(1) and the cost of multi-hop traversals depends on the size of the traversed subgraph, rather than on the total graph size.37
Gremlin, TinkerPop and Cypher (2009–2015)
A parallel ecosystem developed around Apache TinkerPop and its Gremlin graph traversal language, founded in November 2009 by Marko A. Rodriguez and Joshua Shinavier. TinkerPop became a top-level Apache project and Gremlin became the de facto traversal language for a generation of multi-vendor property graph systems including JanusGraph, Amazon Neptune, OrientDB, and DataStax Enterprise Graph.38 Gremlin is functional and imperative in style — chained traversal steps that read like dataflow programs.
Neo4j’s Cypher language, designed by Andrés Taylor at Neo Technology in 2011, took the opposite stylistic decision with declarative, SQL-inspired, ASCII-art pattern syntax such as (a:Person)-[:KNOWS]->(b:Person).39 Neo4j opened the language through the openCypher project in October 2015, attracting partners including Oracle, Databricks, Tableau, and SAP HANA, and producing a Technology Compatibility Kit so vendors could self-certify conformance.40
Other LPG Engines
The decade following Neo4j’s founding produced a dense field of LPG engines. Players in the LPG engine space includes:
JanusGraph, the Apache-licensed successor to Titan.
Amazon Neptune, announced at AWS re:Invent on 29 November 2017 and reaching general availability on 30 May 2018 as a multi-model service supporting both property graphs and RDF
TigerGraph with its proprietary GSQL
ArangoDB and OrientDB as multi-model systems
Memgraph as an in-memory, Cypher-compatible engine targeted at streaming workloads.41
The field has fragmented around storage and execution models but has largely converged on the property graph data model.
GQL: the ISO Standard (2024)
The fragmentation of property graph query languages prompted a multi-year standardization effort. A 2016 Neo4j proposal to other vendors, coupled with a parallel Oracle proposal, was approved as an ISO/IEC JTC 1/SC32 WG3 project in September 2019. The result, ISO/IEC 39075:2024 — Information technology — Database languages — GQL, was officially published on 12 April 2024, making it the first new ISO database query language standard since SQL in 1987.42 GQL fuses ideas from openCypher, GSQL and Oracle’s PGQL with SQL design conventions and is intended to coexist with SQL as a sibling rather than a successor. Most importantly, GQL is defined against the property graph model — not against RDF — and is being implemented by Neo4j, AWS Neptune, TigerGraph, and others as their conformance target.
Technical Comparison
Data model
RDF’s atomic unit is the triple—subject, predicate, object—where subjects and predicates are IRIs or, for subjects and objects, blank nodes. Of note, objects may also be literals.43 The W3C-defined data model is set-theoretic in declaring that an RDF graph is a set of triples. Because predicates are IRIs drawn from globally dereferenceable namespaces, RDF supports global identification by design and adheres to an open-world assumption (OWA) within which the absence of a statement does not imply that it’s false. OWA, proclaims that the absence of data or knowledge is simply unknown. RDF 1.1 formalized named graphs and RDF Datasets, allowing triples to be grouped into addressable subgraphs and giving rise to quad stores.44

An immediate consequence of the classic triple model is that edges cannot natively carry properties. To say “Alice met Bob at 3pm on Tuesday”, one historically had to use RDF reification (four extra triples per edge), an n-ary intermediate node, or named graphs as a side channel. RDF 1.2 closes this gap. With triple terms and the rdf:reifies reification mechanism, an annotation can be attached to a reifier that denotes the underlying proposition, and concrete syntaxes provide ergonomic sugar for the common case — RDF 1.2 Turtle’s annotation block, written :s :p :o {| :source :X ; :certainty 0.9 |} ., asserts the base triple and attaches the metadata to a fresh reifier in a single statement.45 This narrows, though it does not entirely erase, the practical distance between RDF and the LPG model on edge attributes.
The LPG model, by contrast, treats both nodes and relationships as first-class entities, each with an internal identifier, a label (or set of labels), and an arbitrary set of key–value properties.46 There is no native, global, dereferenceable identifier scheme; identifiers are local to the database instance. The standard usage assumption is closed-world. There is no native logical layer, no entailment and historically no standardized schema or constraint language, although Neo4j and others have added their own constraint and graph-type mechanisms, now being standardized through GQL.
A subtle but important distinction emerges with the RDF 1.2 standard. In an LPG, a relationship’s properties are intrinsic to that one edge instance — two KNOWS edges with different since values are simply two edges. In RDF 1.2, a triple term denotes a proposition, and asserting the triple is separate from annotating it; multiple distinct reifiers can describe the same proposition, and a triple term used as an object is not thereby asserted at all.47
This makes RDF 1.2 strictly more expressive for talking about claims, beliefs, and provenance of statements — the difference between “Alice knows Bob, and this edge has weight 0.9” (LPG) and “the source S claims that Alice knows Bob, though we do not assert it” (RDF 1.2). For straightforward edge weights the two are now are now roughly equally easy to express. For nuanced provenance and unasserted claims, RDF 1.2 captures more than an LPG can.
Schema, Semantics and Inference
RDFS and OWL define a formal ontology stack with model-theoretic semantics and decidable description logic fragments (the OWL 2 EL, QL, and RL profiles), enabling reasoners such as Pellet, HermiT, ELK and RDFox to compute entailments such as subclass inference, transitive closure, property chains and consistency checking.48 SHACL provides a closed-world validation model — checking that data conforms to shapes — which deliberately differs from OWL’s open-world inference model.49 As Holger Knublauch has put it, OWL was designed for classification under an open world and SHACL for data validation under a closed world; the two are complementary rather than competing.
LPGs offer no equivalent standardized reasoning layer. Constraints are product-specific, dependent largely on uniqueness, existence, property type constraints in Neo4j and GSQL schemas in TigerGraph. ISO GQL is now standardizing a notion of “graph types” for schema enforcement, but there is nothing comparable to OWL 2’s expressive ontological commitments. Put simply, the lack of a standardized reasoning layer means that LPGs cannot largely support reasoning.
Query Languages
SPARQL is declarative, pattern-based, federated by design via the SERVICE keyword for distributed queries across multiple endpoints, and supports entailment regimes that integrate inference into query answering.50 The companion SPARQL 1.2 update—whose Query and Update documents were Working Drafts as of 23 April 2026 — extends SPARQL to match RDF 1.2, lifting triple-term and reifier patterns into basic graph patterns it is not yet a Candidate Recommendation, so production reliance is premature.51
Cypher and openCypher are also declarative but optimized for path-and-pattern matching expressed in ASCII-art with rich quantified path syntax and Gremlin is functional/imperative and traversal-oriented. Meanwhile, GQL synthesizes Cypher’s pattern style with SQL-style data-definition and procedural constructs.52
While SPARQL excels at set-based pattern matching over triple stores, native LPG engines like Neo4j exploit index-free adjacency to make deep traversals dramatically faster than equivalent joins or queries in either relational or triple-store backends. In the Neo4j in Action benchmark by Jonas Partner and Aleksa Vukotic, run against a one-million-user social network, Neo4j outperformed MySQL by a factor of 1,135 at traversal depth four, with MySQL unable to complete the depth-five query at all within the time limit — a result Neo4j now uses as its canonical evidence for index-free adjacency.53
Interoperability and Standardization
RDF is governed by a coherent suite of W3C Recommendations — RDF 1.1 and now the newly minted RDF 1.2 Recommendation — anchored in dereferenceable IRIs, content negotiation and shared vocabularies and is the standard of choice for FAIR data publication.54 The LPG world was historically fragmented across vendor-specific languages. But with the publication of ISO/IEC 39075:2024, it now has its own de jure international standard. However, identifier governance, vocabulary reuse and cross-organization federation remain less mature than in the RDF stack.
When to Use Each
TL;DR
Use RDF/OWL when the dominant problem is meaning, integration across organizational boundaries, formal reasoning, FAIR/linked-open-data publishing, or long-term governance — particularly in life sciences, healthcare, cultural heritage, libraries, government and any domain anchored in shared vocabularies and global identifiers.

Use a labeled property graph (LPG) when the dominant problem is operational, multi-hop traversal performance on connected data, rich edge attributes (weights, timestamps, confidence) and developer ease of adoption within a controlled application boundary. LPGs are performant at fraud detection, recommendations, network topology, social and supply-chain graphs.
When both axes are equal, considerations and/or requirements, use a hybrid store — either a purpose-built one such as Amazon Neptune, Stardog, or Ontotext GraphDB, or an RDF 1.2–capable triple store paired with Neo4j via neosemantics / R2RML mappings — and budget for the conceptual overhead of maintaining two query surfaces and two graph models. That said, RDF 1.2's native edge-annotation support shifts this formula, weakening one of the historical reasons to reach for an LPG in the first place.
Key Findings — When RDF Wins
Choose an RDF/OWL-based knowledge graph when any of the following conditions is true:
Formal semantics and automated reasoning priorities. If the application must compute entailments — subclassification, transitive properties, property chains, consistency checking, classification of new instances against an ontology — OWL 2 and its DL reasoners offer capabilities no native LPG can match.55
Data integration across heterogeneous sources is the primary problem. RDF’s IRI-based global identifiers, vocabulary reuse and W3C mechanisms such as owl:sameAs and skos:exactMatch are purpose-built for combining data from organizations that must coordinate and reconcile across vocabularies.
Interoperability and long term governance matter. Regulatory, scientific and public-sector domains — life sciences, healthcare, cultural heritage, libraries and government open data — have invested decades in RDF-based shared meaning. FAIR data publication assumes the same principles as RDF and the Semantic Web, founded as part of the same standards groups.56
Provenance and statement-level metadata are first class concerns. PROV-O, named graphs and SHACL provide a coherent toolkit for tracking who said what, when, and on what authority — and RDF 1.2’s rdf:reifies mechanism now makes attaching such metadata to individual statements a native operation rather than a reification workaround.
Federation across distributed datasets is required. SPARQL SERVICE is the only standardized graph federation mechanism with broad implementation support.
Key Findings — When LPG Wins
Choose a labeled property graph when the workload is operational and connected-data performance is the binding constraint:
Deep, real-time traversals on operational data: fraud-ring detection, recommendation engines, network and IT topology, supply-chain analytics, identity resolution, real-time pathfinding. Neo4j’s index-free adjacency and the maturity of the Neo4j Graph Data Science (GDS) library — centrality, community detection, shortest path, link prediction, node embeddings — make LPGs the default choice here.57
Rich edge attributes handled natively. weights, timestamps, confidence scores, transaction amounts. The LPG model puts these properties directly on the relationship. RDF 1.2 now matches this for the common case via annotation syntax, but the LPG remains the more direct fit when edge properties are simply intrinsic attributes of a single edge rather than statements about a proposition.
Developer ease and adoption and time-to-first-query. Cypher’s pattern syntax is the lowest friction graph query language for SQL-trained developers, and the openCypher / GQL convergence ensures a measure of portability.
Application-embedded graphs. transactional workloads with ACID guarantees and millisecond latency on a single cluster.
The Hybrid and Convergent Case
The dichotomy is softening, and the publication of RDF 1.2 in 2026 is signals that the two disciplines are converging by design rather than by accident. Amazon Neptune already supports both property graphs (via Gremlin and openCypher) and RDF (via SPARQL 1.1) in a single managed service, and in August 2024 Amazon Neptune Analytics added the ability to run openCypher queries over RDF graphs under what AWS calls its “OneGraph” initiative.58 Stardog, Ontotext GraphDB and other RDF-native vendors have added edge-property capabilities to bridge to property graph users. Stardog explicitly markets this as joining the two paradigms.59 Neo4j’s neosemantics (n10s) plugin imports and exports RDF and applies OWL/RDFS inferencing within a Neo4j store, while the W3C R2RML standard maps relational data into RDF.
The most significant development is that RDF-star — the long-running effort to give RDF native edge annotations — is no longer a future promise but a standardized capability in RDF 1.2.60 This was an explicit design goal whereby aligning RDF’s expressivity with that of labeled property graphs, the statement-level metadata no longer requires reification gymnastics. The practical result is that “edge properties” are now removed from the list of reasons an RDF practitioner must abandon the stack for an LPG. Convergence research continues from the academic side as well, with proposals to treat RDF, RDF-star and property graphs uniformly as directed acyclic graphs.61
The practical guidance is therefore not “pick one forever” but identify the dominant axis of your problem. If the dominant axis is meaning, integration and long-term governance across organizational boundaries, start with RDF/OWL and use an LPG only where local traversal hot spots demand it — and note that RDF 1.2 removes the edge-property objection that previously pushed such projects toward LPGs. If the dominant axis is operational traversal performance, rich edge attributes and developer velocity within a controlled application boundary, start with an LPG, and reach for RDF when you need to expose your graph as FAIR data or integrate with external ontologies and linked data knowledge graphs. Neptune-style hybrid stores are appropriate when both axes are co-equal.
Recommendations
For a new project, decide in this order. First, ask whether the graph will be published— exposed to external consumers who will not coordinate with you on schema. If yes, RDF is the default. Second, ask whether automated reasoning (subsumption, classification, consistency checking, rule-based inference) is a functional requirement, not a nice-to-have. If yes, RDF with OWL and a DL reasoner (or RDFox, Stardog, or GraphDB with reasoning enabled) is the default. Third, ask whether the binding performance constraint is deep, real-time multi-hop traversal over a graph that fits within an operational database. If yes, a native LPG store (Neo4j, Memgraph) is the default. Fourth, ask whether the application needs rich edge properties (weights, timestamps, confidence) and whether the team values developer ergonomics and SQL-like declarative syntax. If yes, an LPG with Cypher/GQL is the default — though, if RDF already wins on the first two questions, RDF 1.2’s annotation syntax now satisfies the edge-property requirement without a second store. Fifth, if multiple axes are co-equal, default to a hybrid store such as Amazon Neptune or Stardog, accepting the operational cost of supporting two query surfaces.
The benchmarks behind these recommendations are solid. The practical takeaway is that several common justifications for choosing one model over the other don’t always hold up, so it’s worth checking whether your situation actually requires what you think it does.
If your reasoning needs amount to transitive closure and simple subclass inference, an LPG with hand-written recursive Cypher patterns may be enough, and OWL is overkill. If your “external publishing” is really just a stable API serving a single consumer, RDF’s interoperability advantages go unused. And if your traversal bottleneck disappears under a modern columnar SQL engine (DuckDB, ClickHouse) with well-designed materialized views, the LPG performance advantage may not justify standing up a new storage tier.
The edge-property argument for LPG has also weakened. With RDF 1.2 now at Candidate Recommendation and major triple stores beginning to ship conformant support, native statement annotation is increasingly available on the RDF side too. The signal to revisit an LPG-only decision is when two or more of your core RDF dependencies (Jena, RDF4J, Oxigraph, GraphDB, Stardog, Neptune) publish RDF 1.2 conformance.
Caveats
Several uncertainties qualify this analysis. RDF 1.2 is at Candidate Recommendation, not yet a final W3C Recommendation; the W3C process explicitly permits edits and even new features during the CR phase, and the earliest possible Recommendation date is 5 May 2026. Production users should therefore treat the feature set as stable in intent but not frozen, and should track vendor conformance reports rather than assume support. The published RDF 1.2 design also differs from the 2014–2021 RDF-star drafts in ways that matter for migration: triple terms are object-position-only (not subjects), are never self-asserting, and are referentially transparent, and the recommended idiom is rdf:reifies over a triple term rather than the legacy rdf:Statement reification vocabulary. Teams that implemented the earlier “quoted triple” semantics will need to migrate.62 SPARQL 1.2, which is required to query RDF 1.2’s new constructs, was still at Working Draft (23 April 2026) at the time of writing and should not yet be treated as a stable target.63
GQL, by contrast, is a published ISO standard, but vendor conformance is uneven and full feature parity will take several years. For the immediate term, Cypher (Neo4j flavor) and openCypher remain the practical lingua franca. Performance comparisons between RDF triple stores and native LPGs are notoriously workload-dependent and vendor benchmarks (Neo4j’s and Ontotext’s) should be read skeptically and validated against your own workloads. The Partner/Vukotić Neo4j in Action benchmark mentioned above, for example, compares against MySQL with deliberately unindexed join paths and is best read as an illustration of the qualitative asymptotic advantage of index-free adjacency rather than a head-to-head ceiling. Finally, the boundary between “graph database” and “knowledge graph” is itself contested. In industry usage, a “knowledge graph” typically connotes a curated, schema-rich, integrated artifact regardless of the underlying technology, while in W3C usage it more often presupposes RDF/OWL.
In choosing a graph database technology and graph type, it’s best to base selection upon the problems to be solved and the best tools and systems for the job.
Footnotes
Tim Berners-Lee, Semantic Web Road map, W3C Design Issues note, September 1998, <https://www.w3.org/DesignIssues/Semantic.html> ; Tim Berners-Lee, James Hendler, and Ora Lassila, “The Semantic Web,” Scientific American 284, no. 5 (May 2001): 34–43, <https://www.scientificamerican.com/article/the-semantic-web/>.
Renzo Angles and Claudio Gutierrez, “Survey of Graph Database Models,” ACM Computing Surveys 40, no. 1 (February 2008): article 1, <https://doi.org/10.1145/1322432.1322433>.
M. Ross Quillian, “Semantic Memory,” in Semantic Information Processing, ed. Marvin Minsky (Cambridge, MA: MIT Press, 1968), 216–270.
Marvin Minsky, “A Framework for Representing Knowledge,” MIT-AI Laboratory Memo 306, June 1974; reprinted in The Psychology of Computer Vision, ed. Patrick H. Winston (New York: McGraw-Hill, 1975), 211–277, <https://dspace.mit.edu/handle/1721.1/6089>.
Ronald J. Brachman and James G. Schmolze, “An Overview of the KL-ONE Knowledge Representation System,” Cognitive Science 9, no. 2 (April 1985): 171–216, <https://doi.org/10.1207/s15516709cog0902_1>.
Ian Horrocks, Peter F. Patel-Schneider, and Frank van Harmelen, “From SHIQ and RDF to OWL: The Making of a Web Ontology Language,” Journal of Web Semantics 1, no. 1 (2003), <http://www.cs.ox.ac.uk/people/ian.horrocks/Publications/download/2003/HPMW07.pdf>.
Dublin Core Metadata Initiative, history of the DCMI, <https://www.dublincore.org/specifications/dublin-core/dces/> ; ISO 15836-1:2017.
ANSI/NISO Z39.19-2005 (R2010), Guidelines for the Construction, Format, and Management of Monolingual Controlled Vocabularies (Bethesda, MD: NISO, 2005, reaffirmed 2010), <https://www.niso.org/publications/ansiniso-z3919-2005-r2010>.
Alistair Miles and Sean Bechhofer, eds., SKOS Simple Knowledge Organization System Reference, W3C Recommendation, 18 August 2009, <https://www.w3.org/TR/2009/REC-skos-reference-20090818/>.
Meta Content Framework, Wikipedia, <https://en.wikipedia.org/wiki/Meta_Content_Framework> ; R. V. Guha CV, <https://guha.com/cv.html>.
R. V. Guha and Tim Bray, “Meta Content Framework Using XML,” Netscape submission to W3C, 13 June 1997; Tim Bray, “The RDF.net Challenge,” 21 May 2003, <https://www.tbray.org/ongoing/When/200x/2003/05/21/RDFNet>.
Ora Lassila and Ralph R. Swick, eds., Resource Description Framework (RDF) Model and Syntax Specification, W3C Recommendation, 22 February 1999, <https://www.w3.org/TR/1999/REC-rdf-syntax-19990222/> ; W3C Press Release, “W3C Issues Recommendation for Resource Description Framework (RDF),” 24 February 1999, <https://www.w3.org/press-releases/1999/rdf/>.
Berners-Lee, Semantic Web Road map, 1998.
Berners-Lee, Hendler, and Lassila, “The Semantic Web”.
Ian Horrocks et al., “OWL: a Description Logic Based Ontology Language for the Semantic Web,” 2007, <http://www.cs.ox.ac.uk/people/ian.horrocks/Publications/download/2003/HPMW07.pdf>.
Mike Dean and Guus Schreiber, eds., OWL Web Ontology Language Reference, W3C Recommendation, 10 February 2004, <https://www.w3.org/TR/owl-ref/> ; Graham Klyne and Jeremy J. Carroll, eds., Resource Description Framework (RDF): Concepts and Abstract Syntax, W3C Recommendation, 10 February 2004, <https://www.w3.org/TR/2004/REC-rdf-concepts-20040210/>.
Eric Prud’hommeaux and Andy Seaborne, eds., SPARQL Query Language for RDF, W3C Recommendation, 15 January 2008, <https://www.w3.org/TR/rdf-sparql-query/> ; W3C, “Eleven SPARQL 1.1 Specifications are W3C Recommendations,” 21 March 2013, <https://www.w3.org/blog/2013/eleven-sparql-1-1-specifications-are-w3c-recommendations/>.
W3C OWL Working Group, OWL 2 Web Ontology Language Document Overview (Second Edition), W3C Recommendation, 11 December 2012 (first edition 27 October 2009), <https://www.w3.org/TR/owl2-overview/>.
Richard Cyganiak, David Wood, and Markus Lanthaler, eds., RDF 1.1 Concepts and Abstract Syntax, W3C Recommendation, 25 February 2014, <https://www.w3.org/TR/2014/REC-rdf11-concepts-20140225/> ; Jeremy J. Carroll, Christian Bizer, Pat Hayes, and Patrick Stickler, “Named Graphs, Provenance and Trust,” in Proceedings of WWW ’05 (ACM, 2005), 613–622, <https://doi.org/10.1145/1060745.1060835>.
Holger Knublauch and Dimitris Kontokostas, eds., Shapes Constraint Language (SHACL), W3C Recommendation, 20 July 2017, <https://www.w3.org/TR/shacl/> ; Holger Knublauch, “SHACL and OWL Compared,” <https://spinrdf.org/shacl-and-owl.html>.
Timothy Lebo, Satya Sahoo, and Deborah McGuinness, eds., PROV-O: The PROV Ontology, W3C Recommendation, 30 April 2013, <https://www.w3.org/TR/prov-o/>.
R. V. Guha, Dan Brickley, and Steve Macbeth, “Schema.org: Evolution of Structured Data on the Web,” Communications of the ACM 59, no. 2 (Feb 2016): 44–51, <https://queue.acm.org/detail.cfm?id=2857276> ; FOAF Project, <http://www.foaf-project.org/>.
Mark D. Wilkinson et al., “The FAIR Guiding Principles for Scientific Data Management and Stewardship,” Scientific Data 3 (15 March 2016): 160018, <https://doi.org/10.1038/sdata.2016.18>.
W3C, RDF-star Working Group Charter (chartered 29 August 2022), <https://www.w3.org/2022/08/rdf-star-wg-charter/> ; W3C, RDF & SPARQL Working Group Charter (rechartered 1 May 2025), <https://www.w3.org/2025/04/rdf-star-wg-charter.html> ; RDF-star Community Group, Final Report (2021), eds. Hartig, Champin, Kellogg, Seaborne.
Olaf Hartig and Bryan Thompson, “Foundations of an Alternative Approach to Reification in RDF,” arXiv:1406.3399 (June 2014), <https://arxiv.org/abs/1406.3399>.
Olaf Hartig, Pierre-Antoine Champin, Gregg Kellogg, and Andy Seaborne, eds., RDF 1.2 Concepts and Abstract Data Model, W3C Candidate Recommendation Snapshot, 7 April 2026, <https://www.w3.org/TR/rdf12-concepts/> ; W3C, “W3C Invites Implementations of RDF 1.2 Concepts and Abstract Data Model and RDF 1.2 Semantics,” 7 April 2026, <https://www.w3.org/news/2026/w3c-invites-implementations-of-rdf-1-2-concepts-and-abstract-data-model-and-rdf-1-2-semantics/>.
RDF 1.2 Concepts and Abstract Data Model, §3.1 and §3.6 (Triple Terms.
Ibid., §3.6; cf. RDF-star Community Group Final Report (2021), which permitted quoted triples in subject position.
Ibid., §3.6 and §1.5; RDF 1.2 Schema, §5 (`rdf:reifies`, `rdfs:Proposition`), <https://www.w3.org/TR/rdf12-schema/>.
RDF 1.2 Semantics, W3C Candidate Recommendation Snapshot, 7 April 2026, <https://www.w3.org/TR/rdf12-semantics/> (triple terms are non-asserting).
RDF 1.2 Concepts and Abstract Data Model, §3.4 and §3.4.3 (directional language-tagged strings; `rdf:dirLangString`).
Angles and Gutierrez, “Survey of Graph Database Models”.
Emil Eifrem, quoted in Kyle Wiggers, “Database startup Neo4j embraces AI to supercharge growth,” TechCrunch, 19 November 2024, <https://techcrunch.com/2024/11/19/database-startup-neo4j-embraces-ai-to-supercharge-growth/>.
“Neo4j,” Wikipedia, <https://en.wikipedia.org/wiki/Neo4j> ; Neo Technology corporate timeline, “2003 – First 24×7 production Neo4j deployment.”
Clay, “Who is the CEO of Neo4j in 2026? Emil Eifrem’s Bio,” <https://www.clay.com/dossier/neo4j-ceo>.
Wiggers, “Database startup Neo4j embraces AI”.
Neo4j, “Native vs. Non-Native Graph Database,” <https://neo4j.com/blog/cypher-and-gql/native-vs-non-native-graph-technology/>.
Apache TinkerPop, <https://tinkerpop.apache.org/> ; founded November 2009 by Marko A. Rodriguez and Joshua Shinavier.
Nadime Francis et al., “Cypher: An Evolving Query Language for Property Graphs,” Proceedings of SIGMOD 2018, <https://doi.org/10.1145/3183713.3190657> ; Neo4j Cypher Manual, <https://neo4j.com/docs/cypher-manual/current/introduction/cypher-overview/>.
openCypher project, <https://opencypher.org/>.
AWS / Business Wire, “Amazon Web Services Announces General Availability of Amazon Neptune,” 30 May 2018, <https://www.businesswire.com/news/home/20180530006462> ; Amazon Neptune FAQs, <https://aws.amazon.com/neptune/faqs/>.
ISO/IEC 39075:2024, Information technology — Database languages — GQL (Geneva: ISO, 12 April 2024), <https://www.iso.org/standard/76120.html> ; “Graph Query Language,” Wikipedia, <https://en.wikipedia.org/wiki/Graph_Query_Language>.
Cyganiak, Wood, and Lanthaler, eds., RDF 1.1 Concepts and Abstract Syntax.
Carroll, Bizer, Hayes, and Stickler, “Named Graphs, Provenance and Trust”.
RDF 1.2 Turtle, W3C Working Draft (2026), reifiedTriple and annotation-block productions, <https://www.w3.org/TR/rdf12-turtle/> ; RDF 1.2 Concepts, §3.6.
Aidan Hogan et al., “Knowledge Graphs,” ACM Computing Surveys 54, no. 4 (July 2021), article 71, <https://doi.org/10.1145/3447772>.
RDF 1.2 Concepts, §3.6, and RDF 1.2 Semantics.
W3C OWL Working Group, OWL 2 Web Ontology Language Profiles (Second Edition), W3C Recommendation, 11 December 2012, <https://www.w3.org/TR/owl2-profiles/>.
Knublauch and Kontokostas, SHACL .
W3C, SPARQL 1.1 Overview, <https://www.w3.org/TR/sparql11-overview/>.
SPARQL 1.2 Query and SPARQL 1.2 Update, W3C Working Drafts, 23 April 2026, <https://www.w3.org/TR/sparql12-query/> and <https://www.w3.org/TR/sparql12-update/>.
ISO/IEC 39075:2024.
Jonas Partner and Aleksa Vukotic, Neo4j in Action (Manning, 2014), social-network benchmark on a 1,000,000-user database; quoted by Neo4j, “How Much Faster Is a Graph Database, Really?” <https://neo4j.com/news/how-much-faster-is-a-graph-database-really/>.
Hogan et al., “Knowledge Graphs”.
W3C OWL Working Group, OWL 2 Profiles.
Wilkinson et al., “The FAIR Guiding Principles” .
Neo4j, “Native vs. Non-Native Graph Database”; Neo4j Graph Data Science library documentation.
AWS, “Amazon Neptune Analytics now supports openCypher queries over RDF graphs,” August 2024, <https://aws.amazon.com/about-aws/whats-new/2024/08/amazon-neptune-analytics-opencypher-queries-graphs/> ; AWS Database Blog, “Build and deploy knowledge graphs faster with RDF and openCypher,” <https://aws.amazon.com/blogs/database/build-and-deploy-knowledge-graphs-faster-with-rdf-and-opencypher/>.
Stardog, “Property Graphs meet Stardog,” <https://www.stardog.com/blog/property-graphs-meet-stardog/>.
RDF 1.2 Concepts and Abstract Data Model and the RDF 1.2 document suite.
Sven Lieber, Daniel Hernández, et al., “Bridging graph data models: RDF, RDF-star, and property graphs as directed acyclic graphs,” arXiv:2304.13097 (2023), <https://arxiv.org/pdf/2304.13097>.
RDF 1.2 Concepts, §3.6 (object-position-only triple terms); RDF 1.2 Semantics (non-asserting, transparent); RDF 1.2 Schema, §5 (`rdf:reifies` vs legacy `rdf:Statement`eification)
SPARQL 1.2 Query/ Update, Working Drafts, 23 April 2026.
about me. I’m a Semantic Engineer, Information Architect, and knowledge infrastructure strategist dedicated to building information systems. With more than 25 years of experience in enterprise architecture, e-commerce content systems, digital libraries, and knowledge management, I specialize in transforming fragmented information into coherent, machine-readable knowledge systems.
I am the founder of the Ontology Pipeline™, a structured framework for building semantic knowledge infrastructures from first principles. The Ontology Pipeline™ emphasizes progressive context-building: moving from controlled vocabularies to taxonomies, thesauri, ontologies, and ultimately fully realized knowledge graphs.
Professionally, I have led semantic architecture initiatives at organizations including Adobe, where I architected an RDF-based knowledge graph to support Adobe’s Digital Experience ecosystem, and Amazon, where I worked in information architecture and taxonomy. I am also the founder of Contextually LLC, providing consulting and coaching services in ontology modelling, NLP integration, knowledge graphs and knowledge infrastructure design.

I am also a curriculum designer, teacher and founder of The Knowledge Graph Academy, a cohort-based educational program designed to train and up skill future semantic engineers and ontologists. The Academy is the the perfect balance of ontology and knowledge graph theory and practice, preparing graduates to confidently work as ontologist and semantic engineers.
An educator and thought leader, I publish regularly on my Substack newsletter, Intentional Arrangement, where my writing frequently explores the relationship between semantic systems and AI.
More From Intentional Arrangement
Podcasts • Watch and Listen 🎧
Neo4J Event. Context Graphs and Process Knowledge
San Francisco , California
The Data and AI Chief. How Semantic Layers and Ontologies Create Trusted AI
ThoughtSpot Podcast with Cindy Howson
O’Reilly Data Superstream. The Ontology Pipeline™ for AI Systems
O’Reilly
It’s About Data. Knowledge Graphs, Ontologies and Context
It’s About Data with Tony Baer and Matt Housley
Love the history bit. For folks who are interested in more part of history, check out the article I wrote with Prof Claudio Gutierrez on the history of Knowledge Graphs
https://cacm.acm.org/research/knowledge-graphs/
Super article! Detailed and approachable.
I have a distant memory of using the word reify in my first postgraduate essay in 1995 - my first degree is in Latin. My tutor corrected it to deify. Still slightly jarring.