
From Metadata to Meaning
The Knowledge Infrastructure

“The greatest enemy of progress is the illusion of knowledge.”
– John Young, Astronaut
Introduction
Knowledge is dynamic, not static. Knowledge, by definition, is relative to human beings— emerging through brain development, lifelong learning, and the storage of perceived facts in memory. An extended definition of knowledge frames it as a characteristic of social and cultural entities—manifesting in forms such as collective knowledge, knowledge economy, institutional knowledge and knowledge bases. The term knowledge is also used to describe job roles such as knowledge engineer and more broadly, knowledge worker. In his 1959 book Landmarks of Tomorrow, business consultant Peter Drucker coined the term knowledge worker, to describe white-collar workers. In his 1999 Harvard Business Review article, Drucker explains, “...that when people perform the work they are good at and that fits their abilities, they can not only cultivate a more successful career in the knowledge economy, they can ultimately bring more value to the organization.” IBM Education, 2023).
Given the ubiquitous nature of knowledge, one can argue that knowledge management is central to human existence and a foundational element of society. Libraries, archives, and cultural institutions are examples of investments in the human brain trust—preserving cultural memory and supporting scholarly endeavors such as research and innovation. However, a visit inside most enterprise organizations reveals that knowledge and knowledge management are often absent or treated as an afterthought. This harsh reality has been magnified by the recent rise of artificial intelligence (AI), otherwise known as the fourth industrial revolution. Businesses and organizations are quickly discovering that, despite digital ecosystems rich in data, they lack the essential ingredients that AI requires to excel.
Organizations are scrambling to capture structured knowledge to satisfy the demands of AI, desperate to obtain some semblance of knowledge— no matter the cost. The solution is clear: invest in information and knowledge systems and build a robust knowledge infrastructure. When an organization builds its own proprietary knowledge infrastructure, business operations flourish— with or without AI. By investing in this infrastructure, an organization builds its own institutional memory, a kind of brain trust that makes information and knowledge discoverable and interoperable across business processes, machines and people.
In fact, AI services such as ChatGPT, Claude, Llama and Perplexity share a common reason for their high performance: they all rely on robust knowledge infrastructures. These infrastructures provide the training data, Retrieval-Augmented Generation (RAG) and Retrieval-Informed Generation (RIG) implementations, and reference architectures essential for AI to function. In other words, AI depends on information and knowledge— just like humans do.
The Not-So-Distant Past
Up until the public release of ChatGPT on November 30, 2022, organizations, the World Wide Web, schools, and life as we knew it followed a somewhat predictable trajectory. Within organizations, corporate constructs were built around relational databases and product-specific data needs. Business innovations leveraged machine learning algorithms to design engaging customer experiences, driven by market demand for goods and services.
The pre-AI digital era centered organizational infrastructures around relational databases as the core of business operations. Terms like data infrastructure, data warehouses, data lakes, and data architecture were top priority as programs, applications and platforms were built around these critical data assets. In today’s post-AI digital world, these data infrastructures remain important, but lack the requisite information and knowledge, structured in ways that optimize AI performance and output. As the atomic units of information and knowledge, data alone does not make for information or knowledge.
Identity Crisis
The last three years have triggered an identity crisis for organizations. We’ve witnessed overspending on data storage, cloud computing, and AI subscriptions, as everyone scrambled to figure out this AI phenomenon. Melo Ventures reported that businesses spent $13.8 billion on genAI in 2024—five times the $2.3 billion spent in 2023. KPMG’s most recent Quarterly Pulse Survey found that “68% of leaders will invest between $50-$250 million in GenAI over the next 12 months, up from 45% in Q1 of 2024.”
This historic and projected AI spending is astounding, given that most companies continue to struggle with data issues while ignoring the harsh realities of information and knowledge deserts. Perhaps organizations are wishful, hoping AI will manifest context-rich, structured, and semi-structured information and knowledge? However, the same KPMG report suggests some organizational self awareness. “Quality of organizational data is the biggest anticipated challenge to AI strategies in 2025, according to the vast majority of leaders (85%) followed by data privacy and cybersecurity (71%) and employee adoption (46%).”
Great! So We’re Investing in Data Quality?
If data quality concerns and AI infrastructures are taking center stage in 2025, it seems only natural for organizations to invest in information and knowledge infrastructures. But the confidence and clarity is not there. A February 2025, Gartner report cites that 63% of organizations either lack or are unsure if they have the right data management practices to operationalize AI. A July 2024 survey of 1,203 data management leaders warned: “organizations that fail to realize the vast differences between AI-ready data requirements and traditional data management will endanger the success of their AI efforts.” (Gartner, 2025)
If the stakes are so high, you’d expect leaders and organizations to be laser focused on understanding AI-ready data requirements, and present with elevated logic, clear structure, and strategic alignment in AI strategy rooms. Instead, the vast majority of enterprises are falling into doom spirals, holding out hope for some kind of self-healing solution for rigid, unstructured data ecosystems.
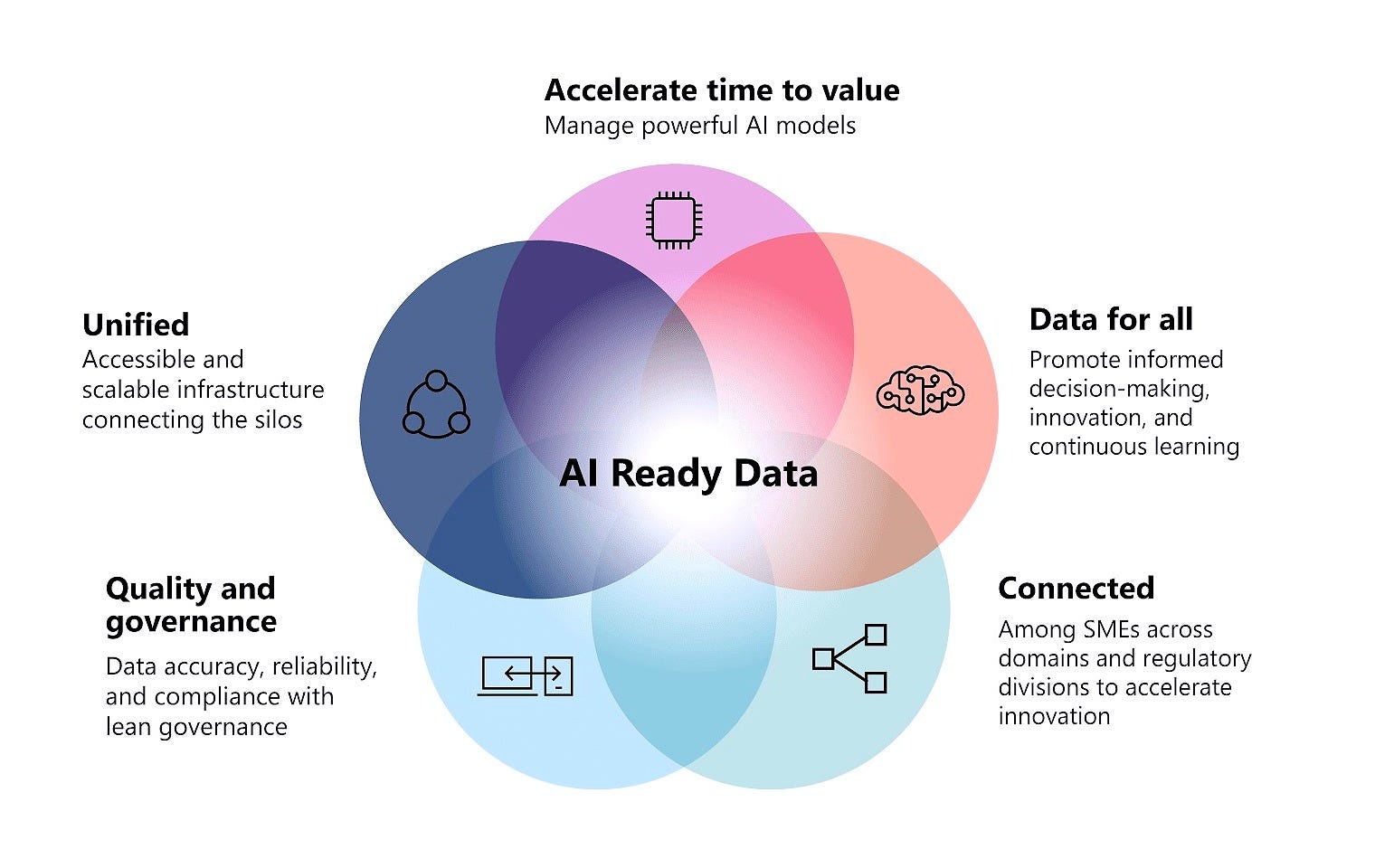
What is AI Ready Data?
Put simply, Ernst & Young describes AI-ready data as “information that is easily combined to form business knowledge. These knowledge assets are used to enhance enterprise AI models, improving AI inference. AI ready data is a higher-value form of data that is used for decisions and actions.” Because information and knowledge management are multidimensional, organizations must mature their data strategies and evolve into knowledge infrastructure strategies—capable of capturing the nuances of business knowledge and rich semantics that give data context and meaning.
An investment in knowledge always pays the best interest
–– Benjamin Franklin
All Knowledge is Not Equal
If knowledge is pervasive and fundamentally human, shouldn’t knowledge management be the primary focus of AI infrastructure and data strategies? The importance of knowledge bases and digital knowledge infrastructures is underscored by AI’s heavy reliance on knowledge sources such as Wikipedia. As noted in a July 2023 New York Times article, “Wikipedia is probably the most important single source in the training of A.I. models.” While not without flaws, occasionally hosting misinformation and disinformation, Wikipedia stands as a massive, crowdsourced knowledge base that should be the envy of every company seeking to leverage AI in products and services. Yet, for some unclear reason, many enterprises are failing to make the connection between their weak knowledge infrastructures and underwhelming AI performance metrics.