
Metadata as a Data Model, Part I
Metadata is a Data Model

Introduction
Metadata is the lowest common semantic denominator in most data ecosystems. Metadata, put simply, is data about data. Metadata can manifest in a multitude of ways—as simple text literal labels, tags applied to resources and documents and even as database schemas that define rows, columns and tables in relational databases. But how do we operationalize metadata to derive semantic context and meaning from metadata? The library and information science domain has been working on refining, iterating and evolving operationalized metadata in digital ecosystems since the advent of computer systems and digital environments with the goal of improving findability, search and discovery for humans and machines.
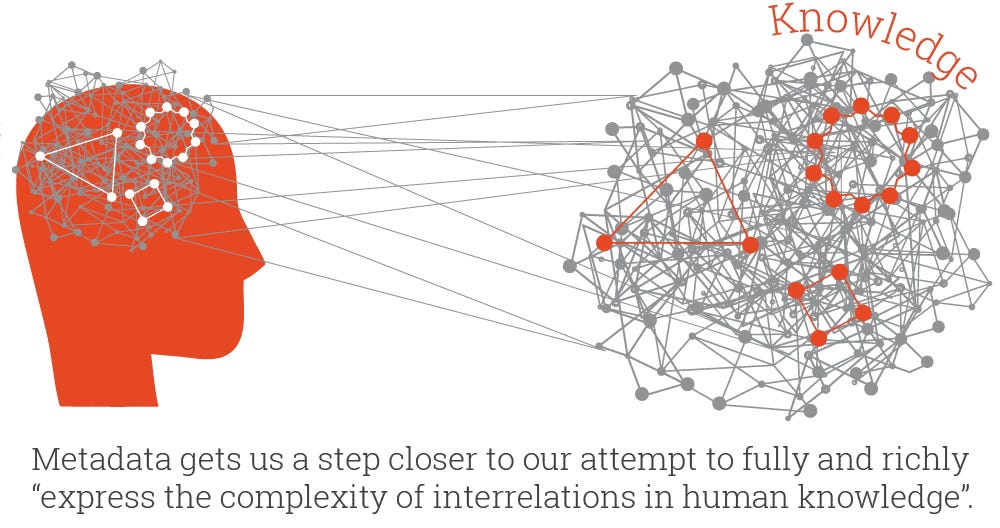
A Systems Thinking Perspective
You may notice that I always incorporate historical backgrounds and narratives in my writing. I cannot imagine designing, modeling or building a system without understanding the historical background of an idea, concept or technology. My undergraduate degree is in history, so perhaps I am a little biased in believing that history is very much a part of systems thinking. For example, most discussions about metadata and metadata systems do not build upon prior art, the historical evidence and work that preceded an idea or technology. In the new, AI-infused information technology movement, metadata discussions tend to revolve around data catalogs, lexical and text labels and API services.
As far as any enterprise technologist is concerned, metadata emerged when computer systems emerged, shallow lenses into the metadata systems. Understanding the centuries-old evolution of metadata brings a systems thinking approach to how to design and build metadata systems capable of transmitting rich descriptive semantics. In other words, to treat metadata as a holistic data model, capable of interoperability and machine readability.
The Enterprise Metadata Conversation
Enterprise data conversations and proposed solutions revolve around solving immediate metadata needs, hot fixes and shiny new technologies, decoupled from the rich history of metadata and relevant systems. To further understand the evolution and foundations of metadata, it is critical that we study the history of metadata, fundamentals of semantics and principles of organizing, to make sense of how to build robust, operationalized metadata systems that scale and extend. And the very concept of a system, is at the heart of understanding semantic, interoperable, extensible metadata. Which is why systems thinking is necessary, to unlock the value of metadata.
The NIST CSRC definition of a system is useful to level-set our understanding of a system: “ A discrete set of resources organized for the collection, processing, maintenance, use, sharing, dissemination, or disposition of information.” By way of this definition, we can further understand the critical importance of a data model to substantiate and proliferate metadata as a first-class data asset.
From their 2015 paper, A Definition of Systems Thinking: A Systems Approach, authors Arnold and Wade work through meta definitions of systems thinking, to arrive at three distinct qualifiers:
elements (in this case, characteristics)
interconnections (the way these characteristics relate to and/or feed back into each other)
a function or purpose
Notably, the least obvious part of the system, its function or purpose, is often the most crucial determinant of the system’s behavior. (Arnold & Wade, 2015, p. 670) Most enterprise systems do not treat metadata as a system of elements, interconnected and designed to serve, with function and purpose.
Often metadata, in modern business-oriented data ecosystems, are reserved for the semantic layer, data catalogs and business glossaries, to be managed by master data management programs with general oversight from a data governance entity. Enterprise metadata is often treated as a byproduct of, or an appendage of a data system, rarely integrated holistically as a logical system and data model. Failing to treat metadata as a holistic system and data model has led to disjointed systems, unable to reconcile disparate metadata elements and incapable of transmitting interoperable semantics, rich with context and meaning.
If metadata serves as a translation layer and functionally, works to translate the syntactic into a common business language, then why aren’t we designing metadata as a system? How do we expect to build for semantics if we are not treating metadata as a holistic system that is both scalable and extensible?
The Library Science Approach
Library science does not evangelize one single metadata standard or one schema to rule them all. Quite the contrary. Library science takes a more holistic approach, realizing that there are base, generalized data fields or elements that can support robust semantics, while also enabling machine readability and interoperability. Essentially, librarians and information scientists operationalize metadata through frameworks, standards and formats so that lexical labels and descriptions are not uncoupled from digital infrastructures frameworks. This is because all library metadata systems are declared data models, woven into the fabric of digital ecosystems, and fundamental to the principles of information retrieval.

From clay tablets to library card catalogs to the web, metadata has persistently been utilized to support access to information and findability. The Library of Alexandria tied tags to scrolls with titles, authors, and subjects, a practice that foreshadowed modern surrogate records and later card catalogs. Libraries have long treated metadata as the scaffolding that makes collections intelligible and findable.
Subscribe to Intentional Arrangement and join a community of readers and thinkers!