

Steal This Deck
A Recap of Stop Betting, Start Building from The Knowledge Graph Conference

Knowledge Graph Conference 2026 · Technology Track

I delivered this talk at the Knowledge Graph Conference under the title Stop Betting, Start Building. I’m renaming the recap Steal This Deck, because the message inside is a brief leadership needs to hear, in order to close the gaps between between what the marketing says about AI and reality. The truth is that AI, especially the vision for agentic AI, needs a knowledge infrastructure to be reliable, interoperable, machine readable and operational. So steal this deck and use parts or the whole presentation. The work doesn’t get done until the people approving budgets understand what they’re approving while also understanding what it takes to get there.

This recap is a summary of my talk, walking through the presentation, section by section. I share this with good will—as I do believe that if a message is delivered with data points to back up each requirement, a collective call to action emerges that is undeniable. Ultimately, the work points to humanity’s shared responsibility, to preserve the tenants of knowledge while building a culture of knowledge sharing.
01 · The Boardroom Pitch
The talk opens with how most AI conversation in 2026 begin—the push towards agentic AI and automation. I break apart the agentic AI cognitive cycle, often labeled ReAct. The framework breaks down into four stages, Perceive → Reason → Act → Adapt. ReAct is short for Reason + Act (Yao et al., 2022) and serves as a prompting paradigm, where a language model alternates thoughts (verbal reasoning) with actions (tool or environment calls), then incorporates the resulting observations back into its next thought. It's the closed loop underneath agentic AI—reason to act, act to reason, repeat. Without it, an LLM is a one-shot responder, not an agent. Autonomous systems that read their environment, plan multi-step tasks, execute without hand-holding and learn from feedback.

But how do we build systems that can reliably sustain ReAct efficiently and at scale?
02 · The Receipts
The first step towards realizing what it takes to build and realize reliable ReAct and agentic systems is to understand what AI research is discovering about the current state of AI. While many organizations build blindly towards marketing claims such as AI being a productivity tool, research is showing an alternative reality.
89% of firms report no productivity impact from AI in three years (NBER, Feb 2026, n=5,937 execs).
80/80 — 80% of firms use generative AI, 80% see no bottom-line impact (McKinsey, 2025).
−19% — experienced developers were slower with AI tools, not faster (METR RCT, 2025).
−14 minutes — net weekly productivity for the average AI-using worker (Foxit/Sapio, March 2026).
The market is bullish but the data is not. This is the gap leadership has to account for and that gap is where this deck lives.
AI is a Knowledge Tool, Not a Data Tool

This is the slide that breaks every assumption underneath most AI strategies in the market today. Organizations are running AI investments on data infrastructure — lakes, warehouses, vector stores, ETL pipelines — and expecting context and reasoning to emerge. But it won’t. AI is a knowledge tool running on data infrastructure, so continuing to approach this as a data problem is setup for failure. This has been proven time and time again.
03 · The Evidence in the Training Data
If you don’t believe me, look at what the models were trained on. The top sources in C4 — the corpus behind Llama and T5 — are not random scrapes. They are linked-data heavy, rich in RDF and triple stores. The top fifteen training sources are graph knowledge structures. Google Patents contain structured records. Wikipedia, #2 of fifteen million sites, is not a traditional structured knowledge graph, but it is a massive, hyperlink-connected network of human knowledge. It serves as a primary source for knowledge graphs, such as Wikidata (RDF graph) and DBpedia RDF graph).1 2 3 4 5 The top fifteen are saturated with RDF, schema.org, controlled vocabularies, provenance citations and linked data.
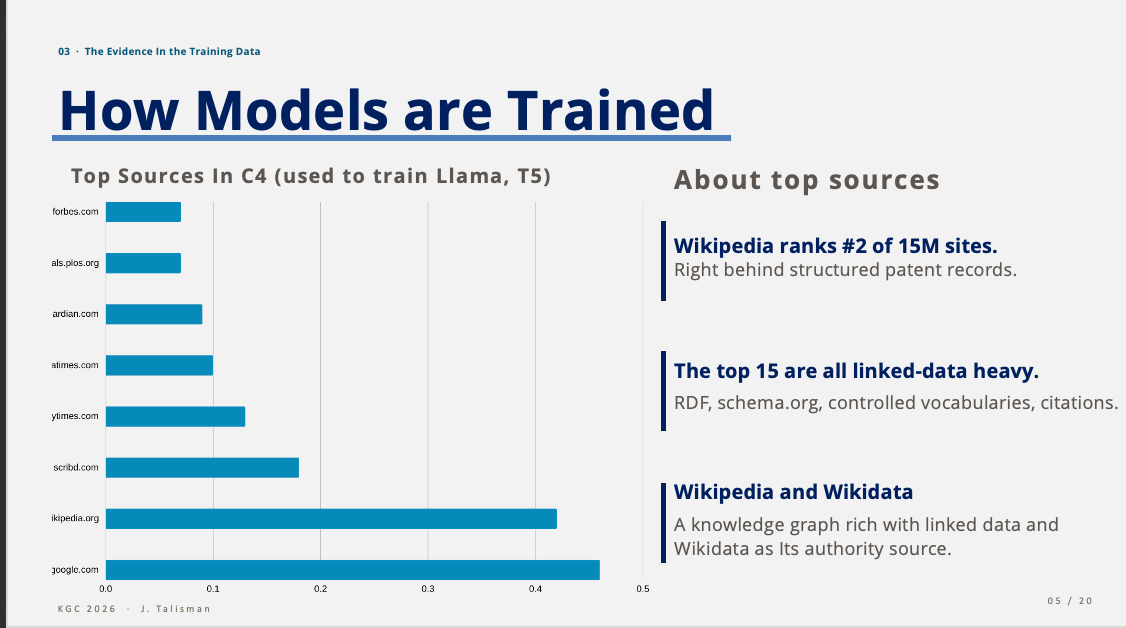
Wikipedia, in particular, is rich with linked data, backed by Wikidata as an authority source and RDF graph. The frontier models learned from rich structured knowledge. They are then deployed against environments that lack structured knowledge. Then we wonder why they hallucinate.
04 · Data, Information, Knowledge
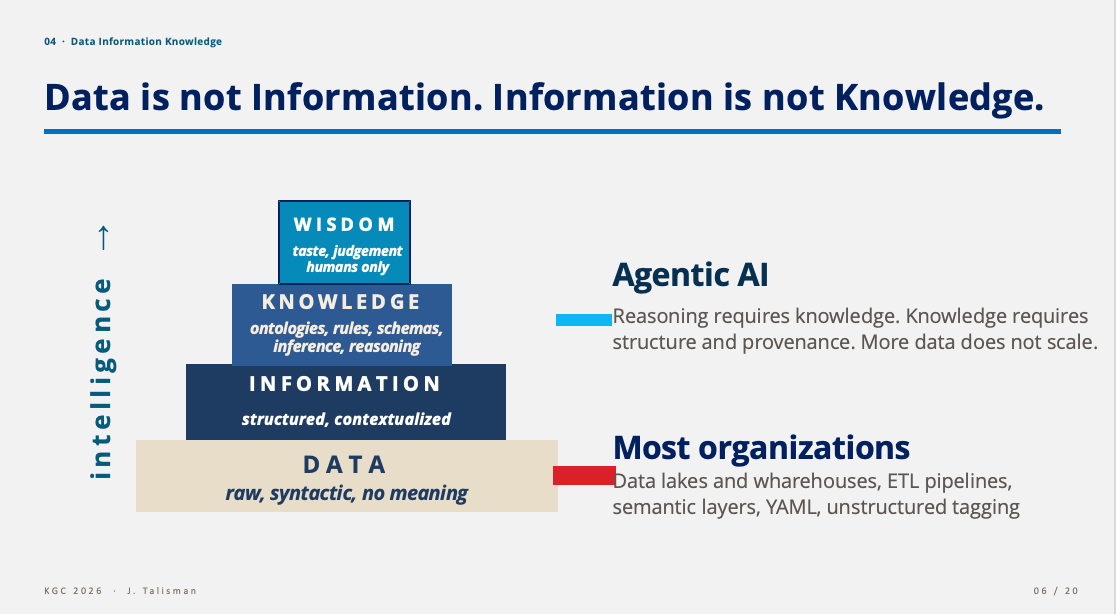
A reminder of the DIKW hierarchy because the industry keeps collapsing the maturity scale into, ‘it’s all data’.
Data — raw, syntactic, no meaning.
Information — structured, contextualized.
Knowledge — ontologies, rules, schemas, inference, reasoning.
Wisdom — taste, judgment. Humans only.
Most organizations are operating mostly on data—lakes, warehouses, ETL and ELT. Many enterprises are dabbling and moving into—information—semantic layers, YAML, unstructured tagging and type systems. Agentic AI relies upon data and information and most importantly, layer three—knowledge. Reasoning requires knowledge. Knowledge requires structure and provenance. More data does not scale.
05 · Why Data Fails

Data-only AI is brittle, opaque and inefficient. Four reasons it fails on its own:
No semantic grounding Without shared definitions and concept mappings, agents can’t reliably identify entities, define relationships or transfer learning across domains.
Opaque decision-making Black-box models can’t produce inspectable decision trails. That’s inadmissible in finance, healthcare, autonomous systems — anywhere consequence lives.
Compute and common sense Models burn enormous resources relearning facts that should have been encoded once. San Francisco is a city in California should not require GPU-weeks.
Brittle generalization Models interpolate well inside the training distribution and falter the moment the world shifts.
06 · The Context Spectrum
I started out this slide by stipulating that this is not another framework. This is the reality we have to grapple with. Where is your organization on the context spectrum? I also highlight the fact that context itself has not been well defined. When we talk about context, what exactly is context? A paragraph, some words, type relationships or descriptive semantic logic? That word—context—is a heavy hitter that is begging for a definition. So for lack of a definition relative to our AI systems, it is best to understand context relative to a spectrum or range.

Every AI system sits somewhere on a spectrum from statistical proximity to formal logical commitment.
Correlation end: vectors, cosine similarity, token co-occurrence. Cheap and almost impossible to audit. Vector RAG, most LLM agents, MCP, A2A.
Middle: typed relations — is-a, part-of, authored-by, cites. Labeled, provenanced, traversable. HippoRAG, AriGraph, Graphiti, A-MEM.
Commitment end: inference, rules, ontological commitments, formal logic. Wikidata, RDF, ontologie,s SHACL, Cyc microtheories.
Most enterprise production AI is camped at the correlation end and pretending to operate at the commitment end. That mismatch proliferates throughout systems, that then hallucinate. An organization will often have mixed systems, a concert of context, each playing off and sometimes against one another. The idea is understanding the system at hand, and where the underlying knowledge exists, in terms of contextual richness.
07 · The Anecdote
Then I broke into story time. I shared my own experience, one year ago, facing a well-funded and well intentioned team attempting to build a semantic entity reconciliation system for agentic AI.
A team of twelve. A massive budget for compute, storage and tooling. Their goal: build “semantic context” for an AI assistant.
The team had devised a strategy with a ginormous budget that I could only dream of. The strategy was to scrape all of Wikipedia for alternative labels or aliases for every term imaginable. The scrape was stripped of all true semantics—triples, identifiers, URIs— retaining only the labels. The labels were then vectorized and mapped to rows and columns in a relational database. No accounting for freshness or semantics. Ironic for a semantic entity reconciliation system.
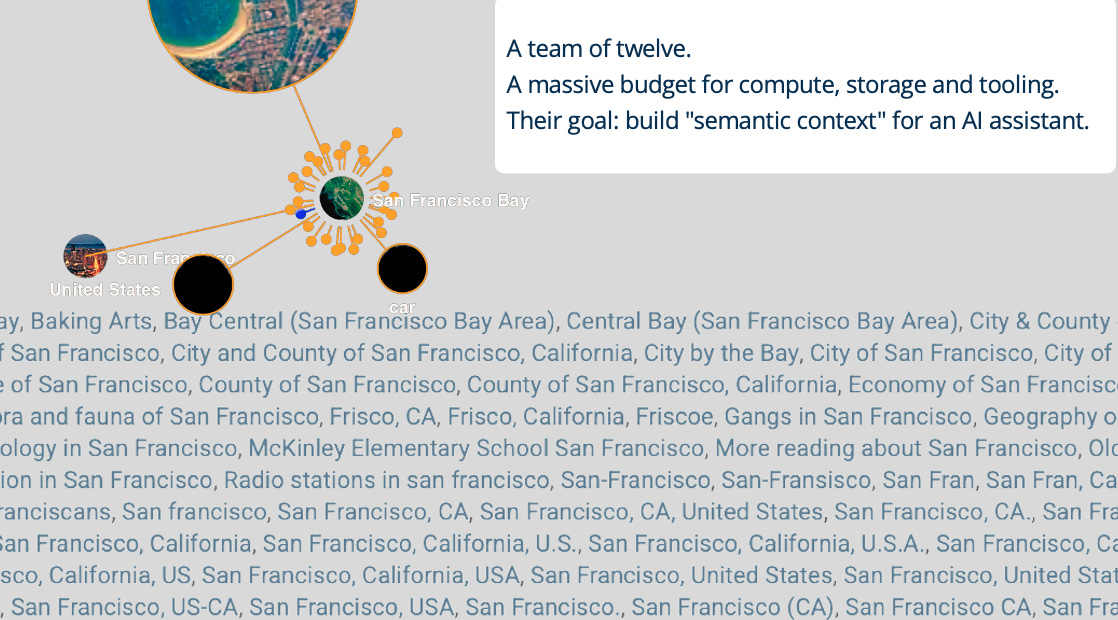
For example, a Wikipedia cluster showing all the ways “San Francisco” is named in the wild — Frisco, San Fran, City by the Bay, City and County of San Francisco, San Francisco CA, San Francisco USA, City of San Francisco, and so on were vectorized and mapped to San Francisco once, with the projected end result being a semantic entity reconciliation system that would bolster an agentic AI system with meaning. I showed the engineer that a simple SPARQL query of the Wikidata RDF graph could render results and downloaded as CSV files. But even better, the SPARQL query can be saved as a RESTful API call, to render a persistent stream of rich semantic context. A much more elegant and semantically rich solution to the semantic entity reconciliation problem.
My proposed solution fell on deaf ears and of course, that semantic entity reconciliation project did not succeed. Imagine the compute, effort and output compared to the more pragmatic approach ,whereby semantic knowledge graphs can be preserved and leveraged for scale, accuracy and persistence, to build real semantic systems.
08 · The Stack — Knowledge Infrastructure, Defined

What is the composite of a knowledge infrastructure? A knowledge infrastructure is built progressively. Each layer makes the next possible.
Controlled vocabularies — the atomic agreement: terms with single, authoritative meanings.
Taxonomies — hierarchical organization. Broader/narrower.
Thesauri — synonyms, equivalences, broad relations, cross-references across vocabularies.
Ontologies — formal commitments. Classes, properties, relations, constraints.
Knowledge graphs — live, queryable, governable, scalable. The architecture of knowledge.
You cannot skip layers. You cannot start at five and reverse-engineer to one. The order matters and the work is sequential.
What Works — Evidence
This is the section leadership most needs to see. The accuracy gap is not closed by buying a bigger model. It is closed by structured knowledge. And the research shows how ontologies solve for LLM accuracy and reliability.
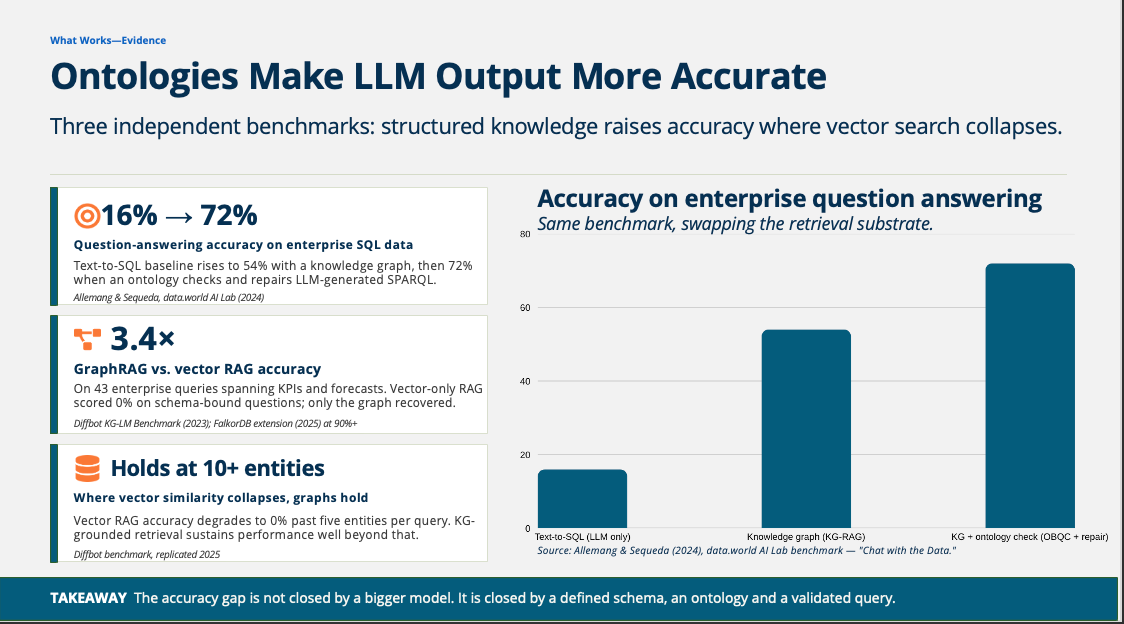
16% → 72%. Question-answering accuracy on enterprise SQL data. A text-to-SQL baseline rises to 54% with a knowledge graph, and 72% when an ontology checks and repairs the LLM-generated SPARQL. (Allemang & Sequeda, data.world AI Lab, 2024.)
3.4×. GraphRAG vs. vector RAG accuracy across 43 enterprise queries spanning KPIs and forecasts. Vector-only RAG scored 0% on schema-bound questions. Only the graph recovered. (Diffbot KG-LM Benchmark, 2023; FalkorDB extension at 90%+, 2025.)
Holds at 10+ entities. Vector similarity collapses to 0% past five entities per query. KG-grounded retrieval sustains performance well beyond that.
Takeaway: the accuracy gap is not closed by a bigger model. It is closed by a defined schema, an ontology, and a validated query.
What Works — Economics
When the domain is defined and modeled, even with a more simplistic controlled vocabulary, the tokenizer compresses, the prompt shrinks and the model stops guessing. This is the “just enough semantics”, the tagline for The Knowledge Graph Conference and coined by Jim Hendler, coauthor of the original 2001 Scientific American Semantic Web article.
−25% tokens. AdaptiVocab (2025) replaces general tokens with domain-specific n-grams. Over 25% input/output token reduction, no quality loss, single-GPU fine-tune.
−20% tokens. eBay (Herold et al., 2025) augmented the tokenizer with e-commerce terms. Sequences shorten up to 20%. Inference latency drops ~30% on long inputs. Predictive quality preserved.
Zero-shot accuracy lift. TAXREC (Liang et al., 2024) injects a taxonomy dictionary into prompts. Efficient token use, controlled feature generation, accuracy gains over plain zero-shot — no fine-tuning required.
What compounds when both grounding and vocabulary are in place—hallucinations are contained and decrease significantly. Ontology-grounded RAG produces the highest performance with minimal hallucination across construction strategies tested.

Ontologies extracted from stable relational schemas perform on par with text-derived ones — built once, not re-inferred per query. Interpretability stays intact: structured retrieval surfaces the path the answer came from while vector similarity does not surface knowledge pathways for lack of logic and reasoning.
Takeaway: defining your terms is the cheapest accuracy and cost lever in the LLM stack.
09 · Thirty-Plus Years of Prior Art
Every “novel” memory paper coming out of frontier labs is rediscovering or trying to reinvent what information scientists and logicians have been working on for decades. There is prior art which is the very foundation of knowledge. Knowledge relies upon prior art and so this is like eating our own dog food from a knowledge infrastructure perspective.
1934 — Paul Otlet. Documents as nodes in a network of typed relations. Traité de documentation.
1951 — Suzanne Briet. An antelope in the wild is not a document. The antelope catalogued in the zoo is.
1993 — John McCarthy. ist(c, p) — formal context as a first-class object. Lifting rules across contexts.
1993 — Tom Gruber. Ontology as a specification of a conceptualization. Shared commitment.
1995 — Doug Lenat (Cyc). Microtheories at industrial scale. The price of common sense, paid up front.
Now — every memory paper. Adding typed edges back, one paper at a time. Discovering descriptive logic and realizing that memory is knowledge.

We call it memory but memory is knowledge. This has been the case for centuries.
10 · The Productivity Paradox
Because one of the primary marketing claims is that AI is a productivity tool, it is only natural that AI is being introduced as such and evangelized as a productivity tool throughout organizations. The reality is that AI isn’t saving time. It is generating work. Without a knowledge backbone, AI’s only measurable output is volume.
74.2% of new web pages contain AI-generated content (Ahrefs, April 2025).
46% of code on GitHub now written by Copilot (Octoverse 2025).
1.7× more issues in AI-authored pull requests (CodeRabbit, 2025).
$9M annual cost of “workslop” for a 10K-person organization (Stanford Social Media Lab).

Welcome to the strip mall of knowledge work where production is cheap but production is not good. Big malls are closing throughout the United States in favor of strip malls because strip malls are more convenient. Much like strip malls, AI is a convenience technology selling itself as a productivity revolution. Without structured knowledge underneath, it generates volume that someone — a human — has to read, verify, correct, and absorb. Net weekly gain for the average AI-using worker: −14 minutes.
11 · The Quality Problem
The lack of knowledge infrastructures is evident in LLM hallucination rates. The reality is that newer models hallucinate more, not less. Hallucination rates across the frontier models are high on specific legal queries, factual questions and clinical case summaries — and only collapse to near-zero in grounded summarization, with sources cited or linked, in context.
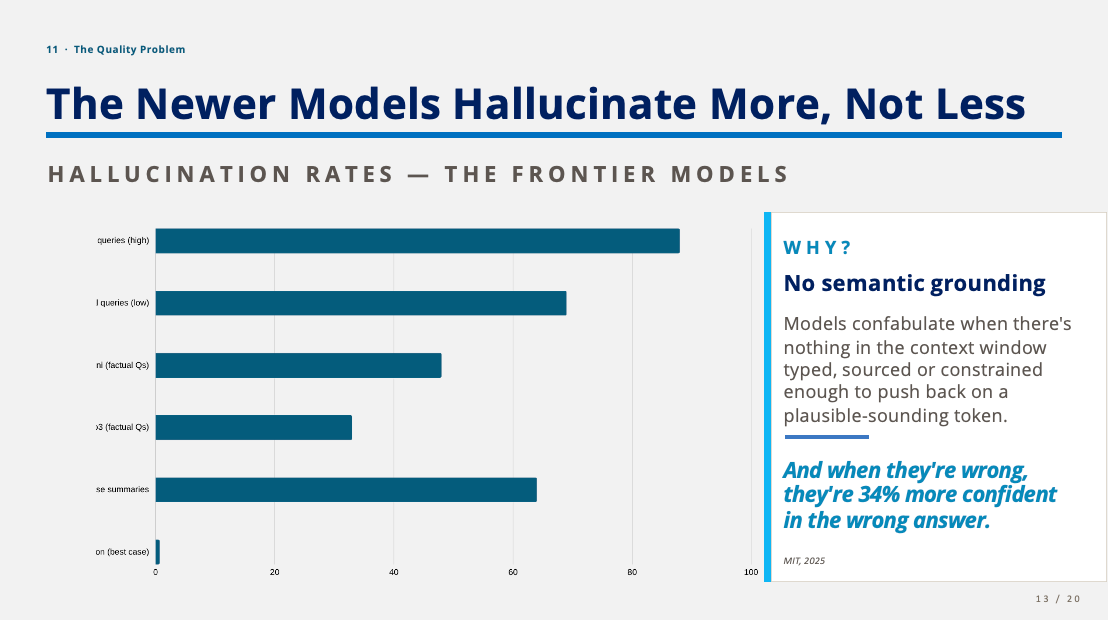
The reason is the same one running through the rest of the deck—no semantic grounding. Models confabulate when there’s nothing in the context window typed, sourced or constrained enough to push back on a plausible-sounding token. And when they’re wrong, they’re 34% more confident in the wrong answer (MIT, 2025).
12 · The Protocol Fallacy
MCP and A2A are transport. Not semantics. They move bytes between endpoints. They do not establish shared meaning. However, the industry is incorrectly positioning the transport layer as semantics.
The protocols solve the connectivity problem, connecting AI systems to tools and data sources, standardizing how an agent calls a function, moving serialized bytes between endpoints, passing strings, JSON blobs and tool schemas.The protocols do not solve for or imbue a system with semantics.

The protocols don’t solve for typed relations between concepts, ontological commitments, provenance chains across systems or two agents referring to the same entity by meaning.
Two agents connected by MCP exchange text bytes. They do not share context. Calling that “interoperability” is the AI and vendor marketing layer. The semantic layer is still missing, and the protocol simply do not provide semantics.
13 · The Cultural Pattern
This slide rolls into the industry-wide culture built around solutions, not problem solving. The industry is optimized to ship solutions, not to own problems. Every incentive points away from understanding problems as workers are fiscally rewarded for shipping solutions quickly and often.

Knowledge work IS the maintenance and problem solving is part of knowledge work. Knowledge work keeps getting cut from budgets and allocated to data teams and AI teams. This is the cultural mechanism by which organizations starve themselves of the very capability their AI strategy depends on.
14 · Mind the Gap
The single most important slide for leadership, accounting for the gap, dimension by dimension, as it relates to LLMs.

Each row is a budget conversation. Each row is also a hiring conversation, a tooling conversation and a governance conversation. The gap is not a technology gap. It is an investment gap masquerading as a technology gap.
ps: Microsoft spellcheck consistently highlights ontologist(s) as a non-existent thing lol
15 · The Unglamorous Part
But a knowledge infrastructure requires a culture shift because knowledge is reliant upon a culture of sharing. Knowledge sharing is the engine of innovation — not the model and not the platform. It is the cultural willingness to break silos and contribute to a shared knowledge base.
What that looks like in practice:

The work required to build a knowledge infrastructure starts with an organization’s ethos and culture. Knowledge work is very different from data work or product work. Knowledge is built upon definitions, agreements, relationships, provenance, interoperability and negotiating meaning with humans and machines. Taxonomies, ontologies and knowledge graphs cannot be sustained without a culture of sharing.
16 · Where to Start
Wondering where to start? No need to boil the ocean as the work and methods are not new. None of this infrastructure requires anyone to invent anything. The standards are open and governed by the W3C and many of the tools used are also open, so there is no vendor lock-in. The ethos behind the Semantic Web, RDF standards and ontologies are built upon concepts such as data sovereignty, in that your data is yours to own, not the property of a vendor or proprietary structures and formats. Semantic Web technologies are structured to be interoperable, machine readable and portable, removing dependencies on vendors and expensive tooling.

Inventory. Take stock of your knowledge assets — vocabularies, glossaries, schemas, undocumented expertise and tacit knowledge elicitation.
Vocab. Build controlled vocabularies. Terms and definitions. Designate authority sources. Assign URIs.
Taxonomy. Organize the vocabulary hierarchically. Broader, narrower, related. Use SKOS and RDF. Test it on real content.
Ontology. Model the domain. Classes, properties, constraints. Reuse standards RDF, OWL, DPROD, SKOS, schema.org, FOAF), FIBO).
Graph. Operationalize. Load into a triple store. Add a reasoner. SPARQL endpoints. SHACL. Wire it into the AI stack.
Govern. This is not a project or a product. This is infrastructure. Stewardship, versioning, growth — forever. Build the culture for knowledge and sharing.
I will add that there are fantastic semantic middleware tools available, which may benefit organizations needing to build, scale and deploy quickly and reliably. However, most of the tooling still enables data sovereignty in that you can export structured knowledge in multiple formats without being locked into the tooling, for production ready taxonomies, ontologies and knowledge graphs. This is where most critically, your ontology is your moat—your IP.
The Close — Reality, the Work
Agentic AI is not a model upgrade away. More knowledge is not the answer. It is a shared language, from which to act.
That’s the talk and why the alternative title is Steal This Deck. The slide deck is the artifact and the brief. The audience that needs the brief is leadership — the people deciding where the AI budget goes and whether knowledge work gets funded as infrastructure or cut as overhead. So far, organizations have largely divested from knowledge and invested heavily in data, without realizing that the problems to be solved rely upon knowledge, not data alone.

The marketing will keep promising autonomy but autonomy requires knowledge. The infrastructure underneath has to be built by humans with methodologies that are grounded in library science, information science, cognitive science and the Semantic Web. This is symbolic AI, the counterbalance to generative AI or predictive, statistical models. Combining generative AI with symbolic AI equals neurosymbolic AI. And this is the sweet spot for reliable, accurate, knowledge-rich AI systems.
The proposition is not for a one-and-done knowledge sprint. Because knowledge is a living, breathing ecosystem, subject to change and drift, the work is a constant and the maintenance requires intention. Knowledge infrastructure must be treated as infrastructure, built with intention. The organizations that close the perception vs reality gap first, will be the ones who finally do the work.
Steal the deck. Take it to your CIO, your CTO, your CDAO. Make the gaps visible and position knowledge as the missing infrastructure necessary to build responsible and reliable AI systems.
Finally, I shared the launch of my upcoming book, The Ontology Pipeline™:, a pragmatic framework for building knowledge infrastructures and symbolic AI:

The entire recording of the talk is available behind a paywall
For paying subscribers: the full deck:
