

Introduction
Agentic Artificial Intelligence is upon us— or so they say. But what does that really mean? Agentic AI refers to systems that can perceive their environment, reason about goals, plan and execute multi-step actions, and learn from feedback, adapting their behavior without constant human direction. In other words, these agents possess agency: the ability to make decisions in dynamic, real-world contexts-—a significant step beyond today’s largely reactive, prompt-driven models.
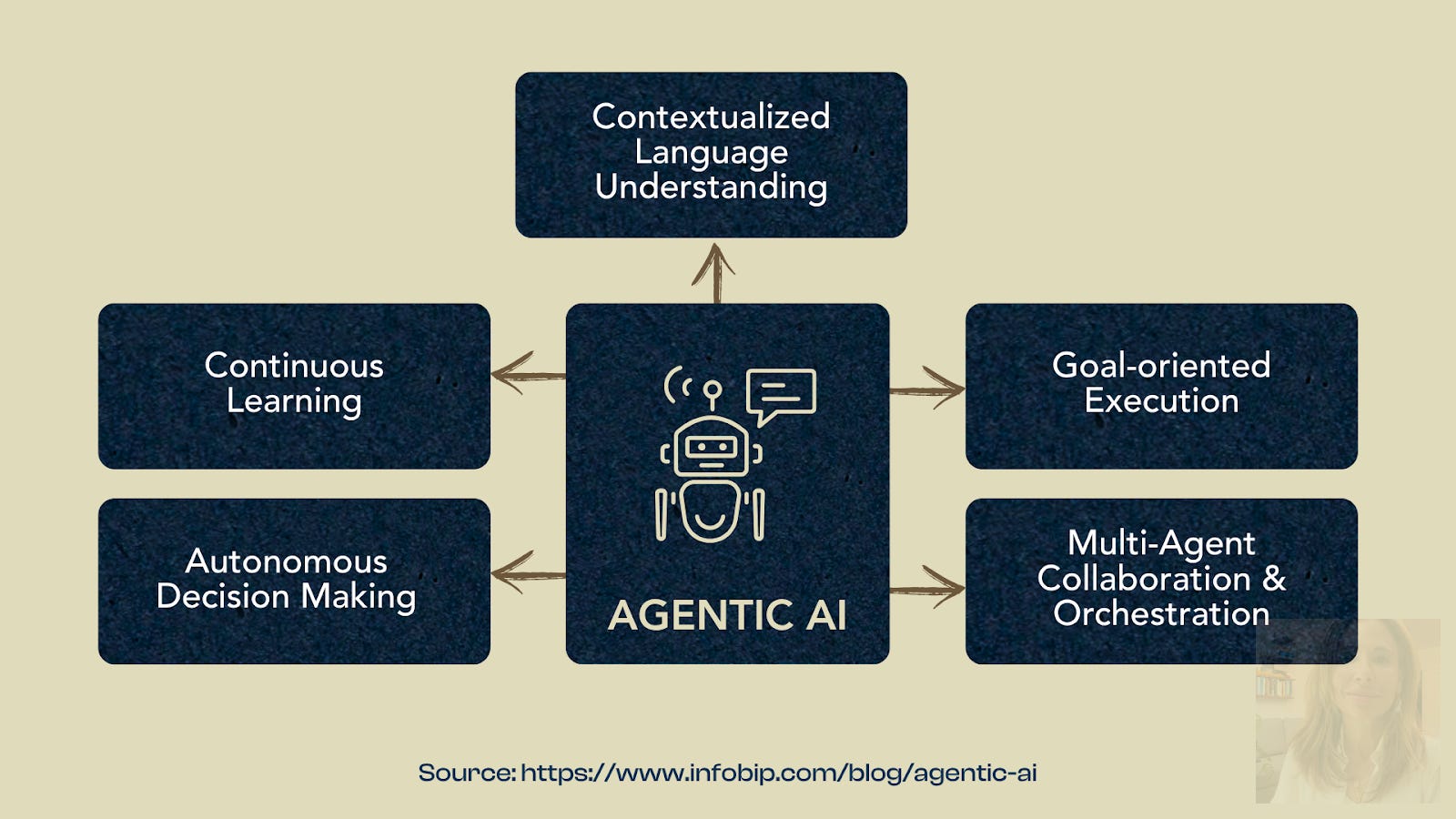
According to IBM, ”Agentic AI is focused on decisions as opposed to creating actual new content, and doesn’t solely rely on human prompts nor require human oversight. Early-stage Agentic AI examples include things like autonomous vehicles, virtual assistants, and copilots with task-oriented goals.”
The new AI race, driven by a fever-pitch marketing bonanza, is hyper-focused on staking the prodigal golden spike into the ground to stake claim victory in achieving Agentic AI. Yet most of the industry is still trying to figure out how to structure and prepare their data just to find any success with generative AI. The likelihood of the typical company achieving effective Agentic AI in the foreseeable future remains low..
AI is a knowledge tool, not a data tool. Until we face this reality head-on, Agentic AI will remain a dream, as companies continue to wrestle with the atomic units of knowledge: data.
AI: A Knowledge Tool
AI, at its core, is a knowledge tool, whether generative or agentic. Yet, while knowledge workers toil to untangle data infrastructures and define semantic layers, vast swaths of corporate and institutional information remain untouched, unstructured, and inert.
Ontologies and knowledge graphs are emerging as tools that promise to enrich data ecosystems with information and knowledge. But the premise of this plan is flawed. If data is the atomic molecule of information, and if information is the foundation of knowledge, then much of the tech industry is simply stirring the pot— hoping that, with enough heat, something will coalesce and magically take form as knowledge.
If AI systems require knowledge to function meaningfully, why are we so reluctant or afraid to build true knowledge infrastructures? And what does knowledge infrastructure even look like?
The Knowledge Infrastructure

The Culture of Knowledge
The concept of knowledge infrastructure is hardly new. Cultural institutions like libraries and archives have long relied on both digital and physical knowledge systems to organize, preserve, and share knowledge. That these institutions operate across both realms highlights the complexity of capturing and modeling knowledge in ways that make data and information findable, interoperable and machine-readable.
So why not learn from the masters? Librarians and archivists live and breathe knowledge infrastructure. Trained in knowledge management frameworks and methodologies, they approach the work with a service-minded approach— supporting both human and machine access to knowledge.

Keep reading with a 7-day free trial
Subscribe to Intentional Arrangement to keep reading this post and get 7 days of free access to the full post archives.