
Why AI Isn't Autonomous (Yet)
Part II: The Context Problem: Why Data Needs Meaning

This article is Part II of a three part series
Introduction
I once met with a machine learning engineer, busy building a semantic entity reconciliation system for an AI assistant. The AI assistant used a SQL-based knowledge( property) graph, dressed up with attributes and values purported to lend meaning. To generate coherent and relevant responses, the system relied heavily on stitching data and mapping techniques.
In the Tradition of Relational Databases
Their approach involved scraping or exporting data from Wikidata and Wikipedia, then processing the scrape using a vector model to extract the relevant semantic or lexical labels. These labels were then mapped into columns and rows— essentially serving as the system’s contextual scaffolding. The lexical labels, she explained, were what qualified the data as “semantic”.
When I pressed further, she revealed that the main purpose of this effort was to gather aliases or alternative labels for known system concepts. “What would happen to the authority URI?” I asked. Her answer: it would be stripped, with only the ID retained. And what about keeping the fresh data? There was no plan for data freshness.
This massive, herculean and episodic effort— staffed with a dozen people, a wide range of expensive tools, and large budgets for compute and storage— was designed to do what a simple linked data, semantic framework would have handled from the start.
Go Native
Ugh. As a practitioner steeped in building and handling knowledge systems, I felt that familiar sinking feeling in my chest. To me, this was a disheartening reflection of the deeply-entrenched, data-centric mindset that continues to define so many AI strategies and architectures— despite everything we should know by now. It was a ridiculously heavy-handed solution to the simple task of lexical labels discovery for entity reconciliation — and somehow calling that “semantic context”. Wasteful, and in my view, fundamentally unscalable.
Why not use and leverage Wikidata and Wikipedia as they’re intended— as native, RDF knowledge graphs? Why not connect via APIs and use SPARQL or SHACL queries, saved as RESTful API calls to supply the necessary REAL semantics to the AI ecosystem? Graph native approaches allow systems to query live, structured knowledge—like Wikidata— on demand, preserving the richness of relationships, meanings and context, rather than flattening everything into static, disconnected labels. Stripping all semantics from a semantic system does not make for meaning or semantics. You don’t get to call it knowledge just because you’ve assigned labels— semantics isn’t just about tagging data, it’s about capturing the deeper meaning, connections and purpose behind the information.
San Francisco As Knowledge
To illustrate the power of a true knowledge infrastructure, I demonstrated to the machine learning engineer what can be derived from an RDF knowledge graph using BabelNet. BabelNet is an “innovative multilingual encyclopedic dictionary, with wide lexicographic and encyclopedic coverage of terms, and a semantic network/ontology which connects concepts and named entities in a very large network of semantic relations, made up of about 23 million entries.” Wikipedia, Wikidata and ontological natural language processing (NLP) knowledge bases are integral parts of BabelNet’s sophisticated knowledge architecture, providing a fabulous source of contextually layered information and knowledge.
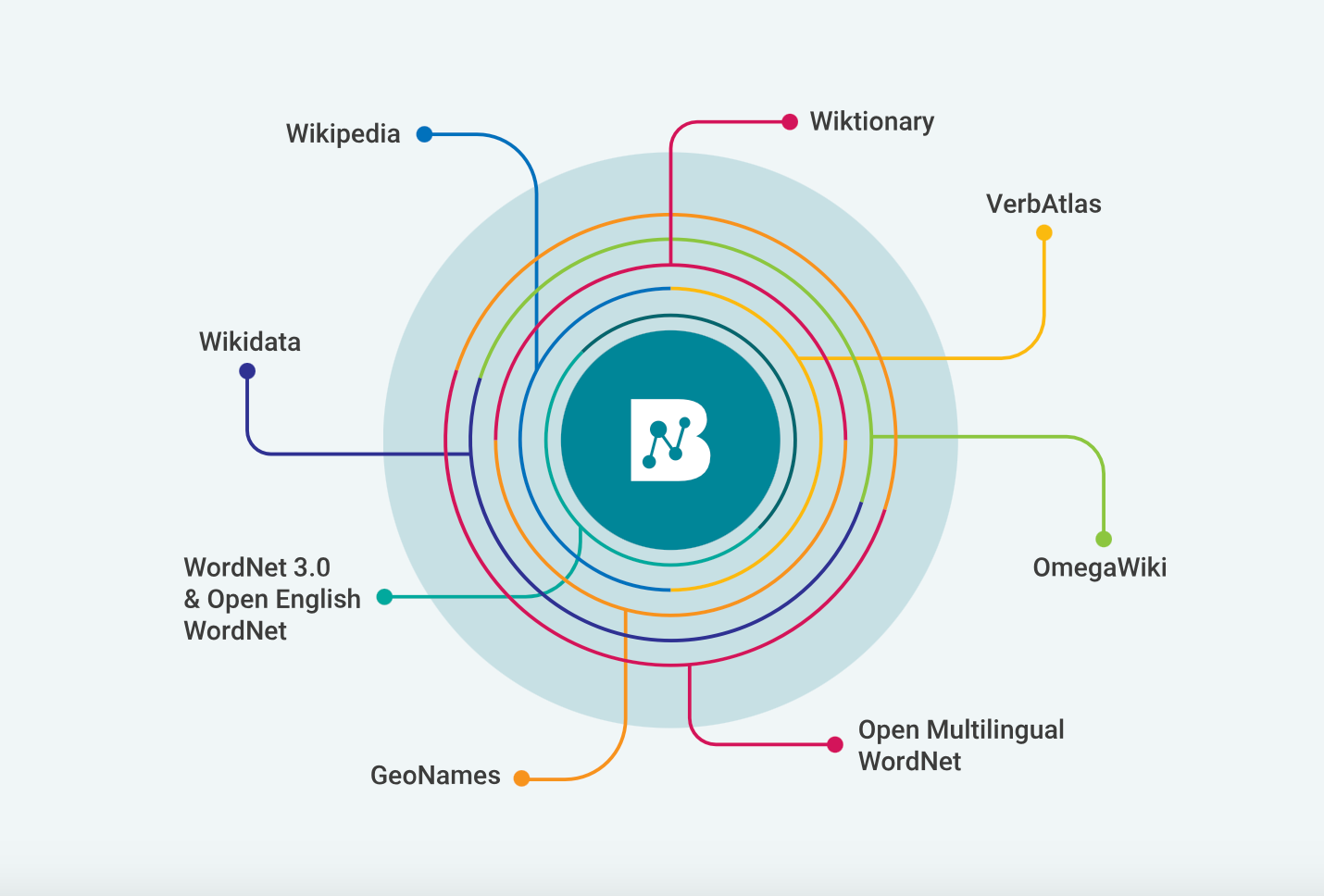
Using the example of aliases for the city San Francisco— one of the use cases the engineer identified—I took her on a journey through its detailed knowledge representation using the following steps.
First, I shared the concept class San Francisco, enriched with a clear definition and basic classification markers such as noun, named entity, city, county and state.

Next, I demonstrated how the GeoNames ontology supplied rich, geographic descriptors, adding contextual layers.
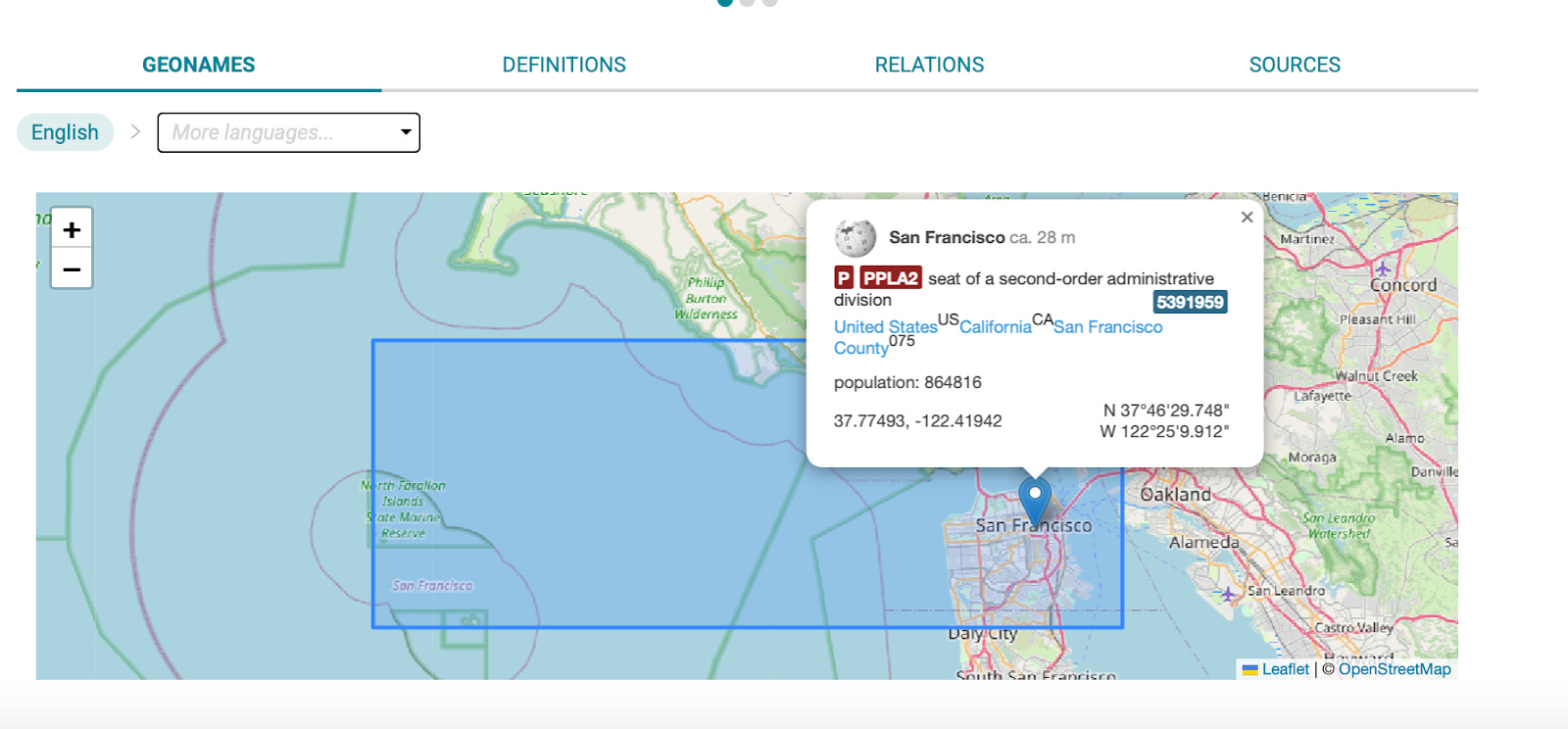
We then explored the definitions derived from various Wiki knowledge bases.

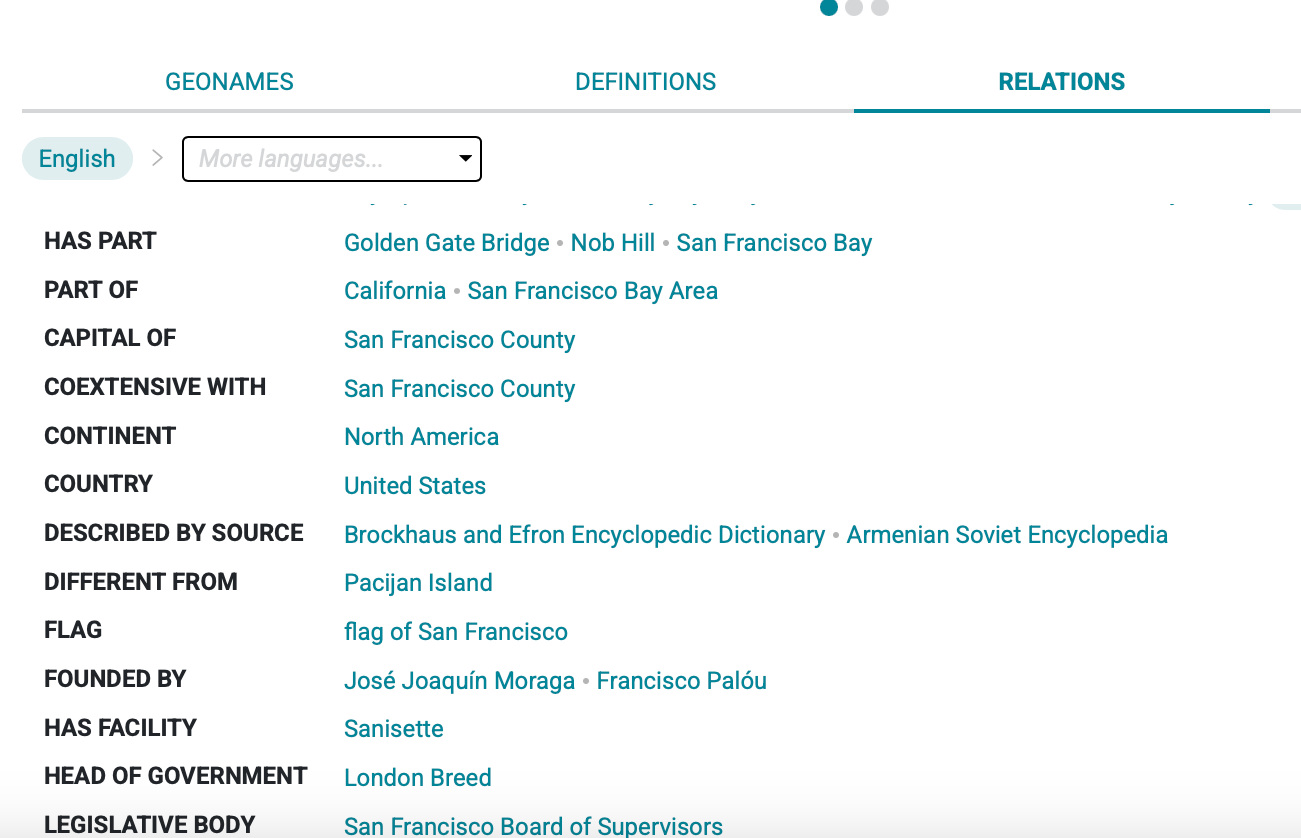
Afterwards, we then visited the Relations tab, where context and meaning deepened through descriptive and logical ontologies. The list of relations was too extensive for the screenshot to capture here.
Finally, we visited the Sources tab, which listed all authority sources for the graph—again, too long to display in full.

At the bottom of the Sources tab, we found the coveted aliases for San Francisco. Additionally, Wikipedia redirects provide further aliases. These redirects reflect Wikipedia’s entity reconciliation methodology, collapsing duplicate and near-duplicate user-generated Wiki pages into single authoritative entities.

Keep reading with a 7-day free trial
Subscribe to Intentional Arrangement to keep reading this post and get 7 days of free access to the full post archives.