

When the Commons Disappears
On Knowledge as Infrastructure and the Proprietary Moat

The United States is losing the AI race to a country that treats knowledge as something that compounds when shared. The cost gap speaks for itself1 DeepSeek’s API charges $0.43 per million input tokens against Claude Opus 4.6’s $4.80, with the output ratio at twenty-eight to one.2 DeepSeek-R1’s reinforcement learning stage cost $294,000 — a figure disclosed in a peer-reviewed Nature paper in September 2025, the first major large language model to undergo independent peer review.3 By February 2026, Chinese models accounted for forty-one percent of downloads on Hugging Face against the US thirty-six-and-a-half percent.4 Seven of the top ten most-downloaded models in November and December 2025 were Chinese.
The gap is explained by the underlying core tenants and architectures prevalent at the majority of US corporations. However, the gap does not explain why one research culture publishes its methods in Nature and another redacts the architecture of its flagship model from its own technical reports. Artificial intelligence is a knowledge-based system. The cultures that treat knowledge as something to share are running a different race than the cultures that treat knowledge as a less important artifact, unworthy of investment and sharing. And the US is quickly devolving into a culture that frowns upon the preservation and sharing of knowledge, the antithesis of science, research and innovation.
The Cliff at GPT-4
OpenAI’s GPT-2 paper in February 2019 disclosed parameter counts, architecture and the WebText dataset. The GPT-3 paper in May 2020 disclosed 175 billion parameters, training compute and a dataset breakdown weighted three-and-a-half times toward Wikipedia.5 The GPT-4 Technical Report, March 14, 2023, states explicitly,
“Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar.”6
Ilya Sutskever, then Chief Scientist, told The Verge the next day that “training data is technology” and that he expected open-sourcing AI would soon look “just not wise.”7 The shift was complete. By December 2024 the o1 system card included no architectural disclosure and forbade users from probing the model’s chain of thought. GPT-4.1 shipped in April 2025 without a system card at all. GPT-5’s August 2025 system card describes a router and discloses nothing about parameters, compute, or training data.8
The April 2018 OpenAI Charter mentioned artificial general intelligence twelve times and stated that the organization’s “primary fiduciary duty is to humanity.” The 2026 update mentions AGI twice but the phrase about humanity is gone.9
The Departures
Ilya Sutskever resigned on May 14, 2024. Jan Leike, his co-lead on the Superalignment team, posted three days later that “safety culture and processes have taken a backseat to shiny products” and that the team had been “sailing against the wind,” denied the twenty percent of compute it had been publicly promised.10 Fortune confirmed the compute commitment was never fulfilled and identified Mira Murati, then CTO, among the executives involved in declining the requests.11 Of the thirteen people who co-founded OpenAI in 2015, three remained by the end of 2024.
The departures were governed by an off-boarding agreement that, as Kelsey Piper documented for Vox, forbade former employees from criticizing the company for the rest of their lives. Acknowledging the agreement existed was a violation of it. Daniel Kokotajlo, a governance researcher, refused to sign and forfeited equity he later described as “about 85 percent of my family’s net worth.”12 When the story broke, Altman wrote on X that he had been “genuinely embarrassed” and had not known. Vox subsequently published documents showing he had signed the relevant provisions.13
In September 2024 William Saunders testified to the Senate Judiciary Committee that during his time at OpenAI “there were long periods of time where there were vulnerabilities that would have allowed me or hundreds of other engineers at the company to bypass access controls and steal the company’s most advanced AI systems including GPT-4.”14 Helen Toner, the former board member who voted to fire Altman in November 2023, told the TED AI Show that the board learned about ChatGPT from Twitter.15


The strategy at Anthropic and Meta follows similar patterns. Anthropic’s Responsible Scaling Policy version 3.0, published February 24, 2026, dropped the pause commitment present in version 1.0 and reclassified key security mitigations as “industry-wide recommendations.”16 Meta restructured Fundamental AI Research under Scale AI founder Alexandr Wang in August 2025, placed Turing Award winner Yann LeCun under his supervision, and instituted new publication restrictions that internal staff described as “a constraint on academic independence.” LeCun left in November 2025 to start his own company. CNBC noted that “While LeCun was always a champion of sharing AI research and related technologies to the open-source community, Wang and his team favor a more closed approach.”17
What Sharing Looks Like
DeepSeek-V2’s May 2024 paper introduced Multi-head Latent Attention with full architectural detail — a memory-architecture innovation that reduced KV cache by 93.3 percent.18 The paper was an act of knowledge sharing, from which other labs could implement the techniques and reproduce the science. Reproducibility being core to scientific research and innovation, all founded upon the availability of knowledge and knowledge sharing.
DeepSeek-V3, in December 2024, was the first paper to publicly document FP8 mixed-precision training at frontier scale. Reading the paper, anyone with sufficient compute could reproduce the approach. The training cost figure — $5.576 million for the official training run — was disclosed alongside a caveat that the figure excluded prior research and ablation experiments. Ablation experiments (or studies) in artificial intelligence are “diagnostic procedures where specific components, features, or layers of a trained AI model are systematically removed or altered.” 19 The goal is to isolate and measure the exact impact of each component on the model’s overall performance, validating design choices and improving transparency. Therefore, omitting the ablation experiences was an intentional act of obfuscating transparency and hiding knowledge. Disclosures are not part of the convention among American labs, which errs towards publishing nothing that may contain disclosures pertaining to architectures.
DeepSeek-R1 shipped in January 2025 on Hugging Face under an MIT license — weights, training methodology, and distilled smaller models on Qwen and Llama backbones, so that researchers without DeepSeek’s compute could still benefit from the work. The September 2025 Nature publication went further, capturing peer review by eight external experts and sixty-four pages of public reviewer correspondence. The Hugging Face engineer Lewis Tunstall called it “a very welcome precedent.” The Nature editorial accompanying the paper observed that “none of the most widely used large language models that are rapidly upending how humanity is acquiring knowledge has faced independent peer review in a research journal. It’s a notable absence.”20
Group Relative Policy Optimization, originally published in DeepSeekMath in February 2024, is now implemented in Hugging Face’s TRL library and used industry-wide. The release was followed by community adoption, which was followed by independent improvements, which were followed by more papers. This is what knowledge compounding looks like when the commons is intact.
Alibaba’s Qwen family has been released continuously from 0.5B to 235B parameters with full technical reports at every scale. By January 2026, Hugging Face counted more than 700 million Qwen downloads and over 113,000 derivative models — the largest single-family ecosystem on the platform.21 Each release is paired with documentation sufficient for fine-tuning, deployment and academic citation. Moonshot’s Kimi K2 introduced the MuonClip optimizer in a July 2025 paper; within months it appeared in research from other Chinese labs and from independent researchers.22 MiniMax-M1 documented Lightning Attention at frontier scale with a $534,700 reinforcement learning bill across three weeks on 512 H800 GPUs — a level of cost disclosure no American lab currently matches. Zhipu’s GLM-4.5, Yi from 01.AI, and Step from StepFun all ship with technical reports.
Clément Delangue, CEO of Hugging Face, called out the cultural differences, stating that “For Chinese AI labs right now, the default is open source. The standard is open source versus in the U.S., the default and the standard is closed source.”23 Nathan Lambert at the Allen Institute for AI noted that “The Chinese labs, through incredibly thorough technical reports and intentional knowledge sharing across labs effectively are de-risking ideas for their peer companies.” His July 2025 essay prophesied that “The next ‘Transformer’-style breakthrough will be built on or related to Chinese AI models, AI chips, ideas, or companies.”24
The publications are how research culture operates — built upon a foundation of knowledge sharing and what the library science domain defines as scholarly communications. The disclosure of architectural innovations is what produces the next architectural innovation, in the same lab and in the labs of competitors who will return the favor in their next paper. When DeepSeek released R1’s weights under the MIT license, that was the natural consequence of a research culture where publication is an obligation to the commons. The open license assumes a cultural posture ,that knowledge belongs to the field that produces it. The American posture asserts the cultural assumption that the next architectural innovation is to be locked, monetized and protected from the researchers most likely to contribute to improvements.
Enlightenment and Darkness
This is a recurring choice made by civilizations throughout history. Every Age of Enlightenment in human history follows the same pattern where the open circulation of knowledge across institutional and political boundaries is a core ingredient of enlightenment. The Islamic Golden Age translated, preserved and extended Greek, Persian, Indian and Chinese scholarship in the House of Wisdom in Baghdad, and the resulting cross-pollination produced algebra, optics and astronomy that Europe would later inherit.

The European Renaissance ran on the printing press, the deliberate translation of Arabic and Greek manuscripts and the correspondence networks that linked scholars from Krakow to Lisbon. The Scientific Revolution and the Enlightenment that followed institutionalized this openness through Royal Societies, peer reviewed journals, scholarly correspondence and public lectures. Newton’s “standing on the shoulders of giants”, so often quoted, was a description of the core driver of scholarship, research culture and innovation. Every age of light has been an age of shared knowledge.

The dark ages, just as consistently, have been ages of knowledge hoarding. When the Library of Alexandria’s contents were lost or sequestered, medieval guilds turned techniques into closely-held trade secrets, Soviet science was siloed by classification or corporations swallowed public research into proprietary pipelines, the consequences rendered the same results throughout history. Innovation slowed, verification became impossible and errors went uncorrected for lack of knowledge sharing required for scientific research and innovation.

Closed systems are historically, the leading indicator of societal decline. The American AI industry’s posture treats frontier model weights, training data and architectural details as trade secrets to be defended rather than findings to be shared, thereby placing it on the wrong side of a knowledge pattern that has been documented for more than two thousand years.
Federal Knowledge Architecture
Within the same timeframe, while US labs were closing their sharing of architectures and research, the federal infrastructure that produced knowledge the AI labs relied upon, came under direct attack. Executive Order 14238, signed March 14, 2025, directed the elimination of the Institute of Museum and Library Services “to the maximum extent consistent with applicable law.” Ironically, Congress had funded IMLS at $294.8 million through September that same day.25
By March 31, approximately seventy-five IMLS employees were placed on ninety-day paid administrative leave, their email accounts disabled and government property collected. Acting Director Keith Sonderling subsequently terminated approximately 1,200 competitive grants and the state-level Library Services and Technology Act grants in California ($15.7 million), Washington ($3.9 million), Connecticut and Massachusetts.26
The Government Accountability Office ruled on August 5, 2025 that IMLS had violated the Impoundment Control Act. Chief Judge John J. McConnell Jr. of the District of Rhode Island permanently blocked the executive order on November 21, 2025. While the grants were eventually restored, the damage was done in the interim The South Dakota State Library discontinued interlibrary loan, the Maine State Library laid off staff and closed its physical location and the Washington State Library lost funding for its Talking Book and Braille Library and for the libraries in nine prison facilities.27
The same period saw the National Institute of Health (NIH) cap indirect cost rates at fifteen percent and terminate 694 grants worth $1.81 billion in seven weeks. The National Science Foundation (NSF) director Sethuraman Panchanathan resigned in April 2025, after the White House ordered him to cut the agency by fifty-five percent and eliminate half its workforce. The NSF subsequently terminated 1,752 grants worth $1.4 billion. On a parallel track, the National Endowment for the Humanities (NEH) used ChatGPT to identify grants for termination, flagging awards containing the words “history,” “culture,” and “identity”. As a consequence, sixty-five percent of NEH staff were fired the same month.28
Librarian of Congress Carla Hayden — the first woman and the first professional librarian to hold the post since 1974 — was fired by a two-sentence email on the evening of May 8, 2025. The next morning the White House Press Secretary cited her “pursuit of DEI” as the cause for dismissal. Deputy Attorney General Todd Blanche was installed as Acting Librarian; Principal Deputy Librarian Robert Newlen, who by protocol should have served, was fired alongside Register of Copyrights Shira Perlmutter.29 Archivist Colleen Shogan had been dismissed three months earlier without the statutorily required notice to Congress. By June, the National Archives had executed a reduction in force eliminating its Office of Innovation.
Approximately eight thousand federal webpages disappeared in late January and early February 2025 along with roughly three thousand datasets — the CDC’s Social Vulnerability Index, the Environmental Justice Index, surveillance data for HIV and tuberculosis, the EPA’s EJScreen, the Climate and Economic Justice Screening Tool, NOAA’s billion-dollar disaster database. The climate.gov team was fired May 31, 2025. Jonathan Gilmour at the Harvard Chan School described what researchers were experiencing, stating “In my lifetime, in the United States I don’t know of another situation where researchers have been this concerned about losing access to data that they’ve had access to their whole career. It’s dire.”30
The Data Rescue Project, a grassroots volunteer consortium organized through IASSIST, RDAP, and the Data Curation Network, was incorporated in February 2025 — within weeks of the takedowns — to coordinate rapid-response preservation of at-risk public datasets grounded in recognized data stewardship principles. That the professional data-curation field was already structured to mobilize this fast underpins the story. The librarians and stewards whose work is most often dismissed as overhead turned out to be the only institutional layer prepared, on a weekend's notice, to keep the public scientific record from disappearing.
By the DRP Portal's own current reckoning, "2,968 datasets across 97 government offices compiled through the efforts of over 500 volunteers" have been preserved — public health surveillance data, environmental justice indices, climate records and economic statistics that would otherwise have vanished from the public record entirely, rescued by professional data curators and librarians working on a volunteer basis to preserve research infrastructure the federal government had funded, produced and then deliberately removed.31
How the Labs Train
The closing of frontier AI labs and the closing of federal data infrastructure describe the same culture. The disposition that treats knowledge as moat in the lab is the disposition that treats knowledge as inconvenience in the agency. The labs that decline to disclose their training data are training on Wikipedia, which is weighted two to three times in nearly every major training corpus despite being roughly three gigabytes compressed.
Major sources of training data includes PubMed Central, built and maintained by the National Library of Medicine. Also of note, the Library of Congress Subject Headings, the most widely used controlled vocabulary in the world, a public-domain product of a federal cataloging tradition. They are training on the corpus of digitized books, in circulation thanks to Carnegie's public libraries. In other words, they are training on the knowledge commons — and the political culture surrounding the commons is now actively leading the charge to dismantle it.
The libraries Andrew Carnegie funded between 1883 and 1929 — 2,509 of them, 1,689 in the United States — were called by their builder and benefactor, “palaces for the people.” The doorways were inscribed Free to the People and Let there be light. The Carnegie grant formula required local governments to provide the site and pledge annual maintenance equal to at least ten percent of construction costs from tax revenue, in perpetuity. This was the operational definition of knowledge as infrastructure—a built environment of access, maintained by collective commitment, indexed by professional standards.32

The Morrill Acts of 1862 and 1890 established the same principle in higher education. Vannevar Bush’s Science: The Endless Frontier in 1945 made it federal policy, arguing that “scientific progress on a broad front results from the free play of free intellects” and warning that “Mendel’s concept of the laws of genetics was lost to the world for a generation because his publication did not reach the few who were capable of grasping and extending it.”33
The architecture Bush proposed produced NSF, an expanded NIH, the National Library of Medicine, MEDLINE, PubMed, PubMed Central and the ARPANET. The same generation that built this infrastructure produced Robert Merton’s articulation of the norms of science — communalism, universalism, disinterestedness, organized skepticism — in which the founding rule was that “secrecy is the antithesis of this norm; full and open communication its enactment.”34 These were moral commitments that made the knowledge commons function for the benefit of innovation, science and enlightenment.
The inflection arrived in 1980. The Bayh-Dole Act allowed universities to retain title to inventions made with federal funding. Rebecca Eisenberg and Arti Rai, writing in Daedalus in 2018, observed what is now easy to overlook: “Most universities were relative newcomers to the patent system, having generally avoided patenting for much of the twentieth century, concerned that patenting conflicted with their mission to disseminate knowledge.”35
Within a generation the patent thicket, Eisenberg and Michael Heller identified an anti-commons in 1998, in which “multiple owners each have a right to exclude others from a scarce resource and no one has an effective privilege of use”, soon thereafter devolving into the operating logic of American innovation policy.36 Elinor Ostrom’s Governing the Commons in 1990 and Understanding Knowledge as a Commons with Charlotte Hess in 2007, documented an alternative where thousands of years of empirical evidence proved that human communities can govern shared resources without enclosure.37 American AI policy in 2026 has ignored both of these bodies of work.
The Recursion
Artificial intelligence systems are knowledge-based systems. They are statistical compressions of a corpus produced by the very knowledge institutions the current US administration is dismantling and the US AI labs are refusing to attribute. The recursion is starting to bite at innovation, forward progress and the very compendiums of knowledge necessary to train AI models.
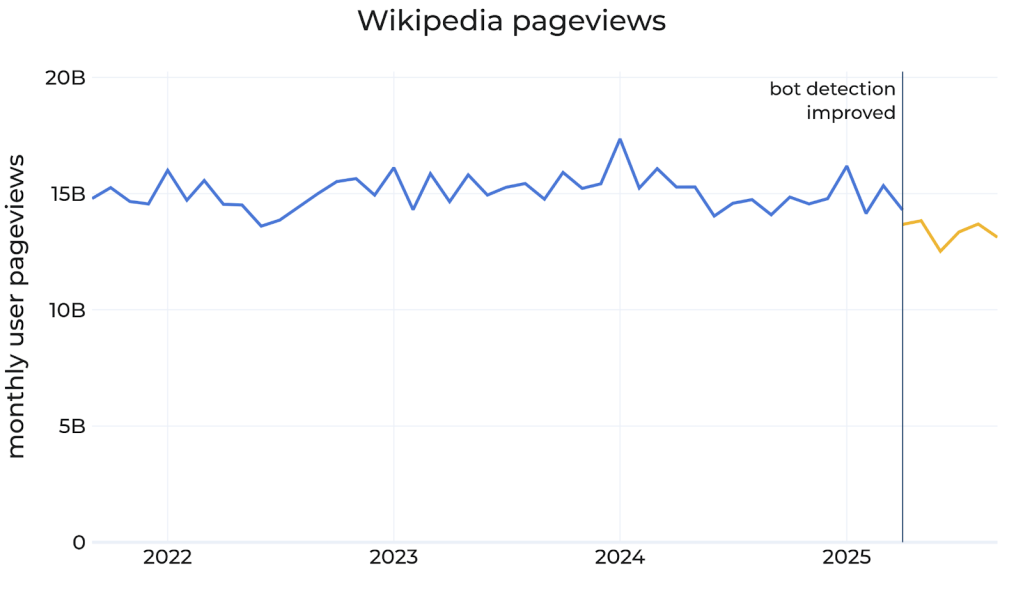
Wikimedia Foundation reported in October 2025 that human page views across all Wikipedia language editions were down eight percent year over year for March through August.38 Organic search traffic to Wikipedia fell from approximately 5.8 billion visits in January 2022 to 4.3 billion in March 2025 — a twenty-six percent decline. Zero-click searches rose from fifty-six to sixty-nine percent in the same window. Pew Research found that only eight percent of users click traditional results when AI Overviews appear.39 Wikipedia is the commons, weighted two to three times in nearly every major training corpus, despite being roughly three gigabytes compressed. The commons is being drawn down faster than it can regenerate, because the systems drawing from it are not driving traffic back to the editors who maintain it.
Stack Overflow shows the same pattern, a stark depiction of the dissolution of the knowledge commons. A study in Scientific Reports in 2024 estimated the platform lost roughly a million daily visitors after the release of ChatGPT, with the decline concentrated among newer users.40 StackExchange data showed question volume by early 2025 down seventy-five percent from its 2017 peak. In May 2024 Stack Overflow announced a partnership selling its data to OpenAI — the same company whose product was destroying its traffic. The platform had originally banned ChatGPT-generated answers for being too often wrong.
The publisher data substantiates the proof, illustrating the dismantling of knowledge networks. AI Overviews appearance rates rose from about six-and-a-half percent of queries in January 2025 to thirty percent of US desktop queries by September. Global publisher Google referrals dropped thirty-three percent year over year. Business Insider lost fifty-five percent and cut twenty-one percent of staff. HuffPost lost fifty. The Daily Mail’s click-through rate fell eighty to ninety percent on queries with AI Overviews.41 The Washington Post laid off roughly a third of its company in February 2026, more than three hundred of an eight-hundred-person newsroom. The publishers that produced the corpus on which the models were trained are being decimated by the products of those models.
The Cloudflare data signals towards the absolute dismantling of underlying knowledge flows. By late 2025 ,the company had blocked 416 billion AI bot requests. TollBit’s Q4 2025 State of the Bots report found that thirty percent of bot scrapes bypassed robots.txt and that forty-two percent of OpenAI’s ChatGPT-User scrapes accessed sites that had explicitly blocked it.42 Toshit Panigrahi at TollBit wrote that “The majority of the internet is going to be bot traffic in the future. It’s not just a copyright problem, there is a new visitor emerging on the internet.” This is consistent with the Dead Internet theory, where bot traffic outnumbers human-led traffic.
Anthropic’s $1.5 billion settlement in Bartz v. Anthropic, finalized September 5, 2025, is the largest publicly reported copyright recovery in US history.43 It covers approximately 500,000 books, where the valuation of each work was estimated to be roughly $3,000 USD. Anthropic had downloaded more than seven million books from LibGen and Pirate Library Mirror, violating the legal copyrights protecting each book. Judge William Alsup ruled training itself as “exceedingly transformative” and a fair use, but found that downloading pirated books to build a permanent library was “inherently, irredeemably infringing.”
Judge Vince Chhabria in Kadrey v. Meta declined to find liability on the arguments before him, but articulated the underlying problem with clarity, stating that “Generative AI has the potential to flood the market with endless amounts of images, songs, articles, books, and more…companies are creating something that often will dramatically undermine the market for those works, and thus dramatically undermine the incentive for human beings to create things the old-fashioned way.”44
The Disposition and the Race
Ilya Sutskever told NeurIPS in December 2024 that “pre-training as we know it will unquestionably end… because we have but one internet.” He called data “the fossil fuel of AI” and said the industry had “achieved peak data.”45 Epoch AI, the nonprofit that tracks long-run machine learning trends, projects that frontier models will train on datasets equal to the entire stock of publicly available human-generated text between 2026 and 2032 — a forecast that is only intelligible if you have already decided, at the level of basic premises, that human knowledge is a deposit to be extracted rather than a system to be invested in.46
The Shumailov Nature paper on model collapse — published the same year — established that recursive training on synthetic data produces “irreversible defects” in which “tails of the original content distribution disappear.”47 The only reliable and lasting resource is genuine human knowledge work. The institutions that produce, curate, classify,and preserve it are being defunded, deprofessionalized and litigated against ,simultaneously.
Chinese AI labs are publishing because their incentive structure rewards publication, and because the cultural assumption that knowledge compounds when shared has not been bred out of their working scientific generation the way it has been bred out of the US. The Mertonian norm — that secrecy is the antithesis of science and full, open communication its enactment48— is operating in Hangzhou and Beijing, but not San Francisco. The asymmetry is evident in technology leaderboards, AI lab disclosure practices and in the predominating culture of knowledge production. If examined according to the ethos of the knowledge commons, the leaderboards are really measuring which research culture remembers that knowledge is a commons, and which has conveniently forgotten.
And here is the irony AI cannot escape. AI is a knowledge-based system being built by a culture that has decided knowledge is not a system worthy of investment or sharing. The labs piracy of the world’s libraries to train their models, federal data infrastructure that produced the public scientific record for a century being dismantled in real time. The library science profession that maintains the controlled vocabularies, the metadata schemas, the scholarly archives and the cataloguing standards upon which both AI labs and agencies depend, being treated as extraneous overhead all while fear mounts around running out of training data, necessary for innovation and progress.
The American AI industry’s competitive disadvantage is not so much a research problem or a compute problem. There is an overarching cultural problem within which a civilization that has trained itself, over forty years, to treat the commons as something to extract from rather than something to invest in. The hallmark and tell tale sign of a society sliding into darkness rather than building towards enlightenment.
Footnotes
The cost and efficiency asymmetry between US and Chinese AI labs is documented at the level of industrial structure in Matt Stoller, “The Efficiency Moat: Why China Is Beating the U.S. on AI… And Everything Else,” BIG by Matt Stoller (Substack), May 2026, https://www.thebignewsletter.com/p/the-efficiency-moat-why-china-is, drawing on data from Azeem Azhar and Hannah Petrovic, “Inside the Chinese AI labs where America’s AI controls created its toughest competition,” Exponential View , May 13, 2026.
Azhar and Petrovic, “Inside the Chinese AI labs.”
Daya Guo et al., “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning,” Nature 645, no. 8081 (September 17, 2025): 633–638, https://doi.org/10.1038/s41586-025-09422-z. See also the Nature editorial accompanying the paper, “Bring us your LLMs: why peer review is good for AI models,” Nature, September 17, 2025.
Hugging Face platform statistics, February 2026; see also U.S.-China Economic and Security Review Commission, “Two Loops: How China’s Open AI Strategy Reinforces Its Industrial Dominance,” March 2026, https://www.uscc.gov/sites/default/files/2026-03/Two_Loops–How_Chinas_Open_AI_Strategy_Reinforces_Its_Industrial_Dominance.pdf.
Tom B. Brown et al., “Language Models are Few-Shot Learners,” arXiv:2005.14165, May 28, 2020. Wikipedia was sampled 3.4 epochs against weights of 0.6 epochs for Common Crawl.
OpenAI, GPT-4 Technical Report, arXiv:2303.08774, March 14, 2023, 2.
James Vincent, “OpenAI co-founder on company’s past approach to openly sharing research: ‘We were wrong,’” The Verge, March 15, 2023.
For the OpenAI o1 system card, see https://openai.com/index/openai-o1-system-card/. For the GPT-5 System Card, see https://openai.com/index/gpt-5-system-card/, August 7, 2025.
OpenAI Charter, April 9, 2018, https://openai.com/charter/. For comparative analysis of the 2026 revision, see “OpenAI Rewrites Its Founding Principles for the First Time in Eight Years,” ChatAI ,2026.

Jeremy Kahn, “OpenAI promised 20% of its computing power to combat the most dangerous kind of AI — but never delivered, sources say,” Fortune, May 21, 2024.
Kelsey Piper, “ChatGPT can talk, but OpenAI employees sure can’t,” Vox , May 17, 2024.
Kelsey Piper, “Leaked OpenAI documents reveal aggressive tactics toward former employees,” Vox, May 22, 2024.
William Saunders, “Written Testimony,” Senate Judiciary Subcommittee on Privacy, Technology, and the Law, September 17, 2024, https://www.judiciary.senate.gov/imo/media/doc/2024-09-17_pm_-testimony-_saunders.pdf.
Helen Toner, interview, The TED AI Show, May 28, 2024.
“Anthropic’s RSP v3.0: How it Works, What’s Changed, and Some Reflections,” GovAI, February 2026.
Jonathan Vanian, “Meta chief AI scientist Yann LeCun is leaving to create his own startup,” CNBC, November 19, 2025.
DeepSeek-AI, “DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model,” arXiv:2405.04434, May 2024.
Wikipedia contributors, "Ablation (artificial intelligence)," Wikipedia, The Free Encyclopedia, accessed May 17, 2026, https://en.wikipedia.org/wiki/Ablation_(artificial_intelligence).
“Bring us your LLMs,” *Nature*, September 17, 2025. For GRPO, see Zhihong Shao et al., “DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models,” arXiv:2402.03300, February 2024.
Qwen Team, “Qwen2.5 Technical Report,” arXiv:2412.15115, December 2024; Qwen Team, “Qwen3 Technical Report,” arXiv:2505.09388, May 2025.
Moonshot AI, “Kimi K2: Open Agentic Intelligence,” arXiv:2507.20534, July 2025; MiniMax, “MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention,” arXiv:2506.13585, June 2025.
Clément Delangue, quoted in “Why China Is Winning The Open Source AI Race,” Yahoo News, March 2026.
Nathan Lambert, “The American DeepSeek Project,” Interconnects, July 2025.
Executive Order 14238, “Continuing the Reduction of the Federal Bureaucracy,” March 14, 2025; Pub. L. 119-4.
American Library Association, “FAQ: Executive Order Targeting IMLS,” https://www.ala.org/faq-executive-order-targeting-imls; American Library Association v. Sonderling, No. 1:25-cv-01050 (D.D.C., filed April 7, 2025).
U.S. Government Accountability Office, Institute of Museum and Library Services — Applicability of the Impoundment Control Act to Reduction of Agency Functions, B-337375, August 5, 2025; Rhode Island v. Trump, opinion of Chief Judge John J. McConnell Jr., D.R.I., November 21, 2025.
For NIH, see NOT-OD-25-068, February 7, 2025, and U.S. GAO findings of August 2025. For NSF, see Council on Strategic and Statistical Affairs, “NSF Releases List of Terminated Grants,” May 2025. For NEH, see Liam Knox, “‘Draconian’ Layoffs, Grant Terminations Come for the NEH,” Inside Higher Ed, April 14, 2025, and American Council of Learned Societies v. Vought, ruling of Judge Colleen McMahon, S.D.N.Y., May 7, 2026.
For the Hayden dismissal, see Andrew Albanese, “Librarian of Congress Carla Hayden Is Fired,” Library Journal , May 9, 2025.
Naomi Schalit, “Researchers rush to preserve government health data,” The Journalist’s Resource, February 2025; see also KFF, “A Look at Federal Health Data Taken Offline,” 2025.
Data Rescue Project Portal, homepage, accessed May 2026, https://portal.datarescueproject.org/. The portal aggregates rescue work coordinated through three professional associations — IASSIST (International Association for Social Science Information Services & Technology), RDAP (Research Data Access and Preservation Association), and the Data Curation Network — and integrates contributions from allied initiatives including Public Environmental Data Partners, Safeguarding Research & Culture, the Internet Archive’s End of Term Web Archive, and ICPSR’s DataLumos. See also Mike Schneider, “Why are data nerds racing to save US government statistics?“ AP News, July 24, 2025.
Eric Klinenberg, Palaces for the People: How Social Infrastructure Can Help Fight Inequality, Polarization, and the Decline of Civic Life (New York: Crown, 2018), 32. For a critical reading of the period, see Robert Lee and Tristan Ahtone, “Land-Grab Universities,” High Country News, March 30, 2020.
Vannevar Bush, Science, The Endless Frontier: A Report to the President (Washington, D.C.: U.S. Government Printing Office, July 1945), https://www.nsf.gov/od/lpa/nsf50/vbush1945.htm.
Robert K. Merton, “A Note on Science and Democracy,” Journal of Legal and Political Sociology 1 (1942): 115–126.
Rebecca S. Eisenberg and Arti K. Rai, “Universities: The Fallen Angels of Bayh-Dole?,” Daedalus 147, no. 4 (Fall 2018): 76–89.
Michael A. Heller and Rebecca S. Eisenberg, “Can Patents Deter Innovation? The Anticommons in Biomedical Research,” Science 280, no. 5364 (May 1, 1998): 698–701.
Elinor Ostrom, Governing the Commons: The Evolution of Institutions for Collective Action (Cambridge: Cambridge University Press, 1990); Charlotte Hess and Elinor Ostrom, eds., Understanding Knowledge as a Commons: From Theory to Practice (Cambridge, MA: MIT Press, 2007).
Marshall Miller, “How AI is changing how people access knowledge online,” Wikimedia Foundation blog, October 20, 2025.
DataReportal, Digital 2025 April Statshot Report; Similarweb, AI Platform Trends Q2 2025; Pew Research Center, “Google users are less likely to click on links when an AI summary appears in the results,” July 22, 2025.
Maria del Rio-Chanona et al., “The consequences of generative AI for online knowledge communities,” Scientific Reports 14 (2024).
Chartbeat and Press Gazette publisher data, 2025.
TollBit, State of the Bots Q4 2025; Matthew Prince interview, WIRED Big Interview, October 2025.
Bartz v. Anthropic, No. 3:24-cv-05417 (N.D. Cal.), summary judgment opinion of Judge William Alsup, June 23, 2025; settlement announced September 5, 2025.
Kadrey v. Meta Platforms, Inc., No. 3:23-cv-03417 (N.D. Cal.), opinion of Judge Vince Chhabria, June 25, 2025.
Ilya Sutskever, NeurIPS keynote, December 13, 2024.
Pablo Villalobos, Anson Ho, Jaime Sevilla, Tamay Besiroglu, Lennart Heim, and Marius Hobbhahn, Will We Run Out of Data? Limits of LLM Scaling Based on Human-Generated Data, Epoch AI (June 2024), arXiv:2211.04325v2, https://epoch.ai/blog/will-we-run-out-of-data-limits-of-llm-scaling-based-on-human-generated-data; presented at the 41st International Conference on Machine Learning, Vienna, Austria, July 2024.
Ilia Shumailov et al., “AI models collapse when trained on recursively generated data,” Nature 631 (July 24, 2024): 755–759; Pablo Villalobos et al., “Will we run out of data? Limits of LLM scaling based on human-generated data,” arXiv:2211.04325, June 2024.
Robert K. Merton, “The Normative Structure of Science,” in The Sociology of Science: Theoretical and Empirical Investigations (Chicago: University of Chicago Press, 1973), 267–278. Merton’s four norms — communalism, universalism, disinterestedness, and organized skepticism (CUDOS) — describe the institutional ethos of modern science, with communalism specifically requiring that “the substantive findings of science are a product of social collaboration and are assigned to the community… secrecy is the antithesis of this norm; full and open communication its enactment.” Originally published in 1942 as “A Note on Science and Democracy,” Journal of Legal and Political Sociology 1: 115–126.
about me. I’m a Semantic Engineer, Information Architect, and knowledge infrastructure strategist dedicated to building information systems. With more than 25 years of experience in enterprise architecture, e-commerce content systems, digital libraries, and knowledge management, I specialize in transforming fragmented information into coherent, machine-readable knowledge systems.
I am the founder of the Ontology Pipeline™, a structured framework for building semantic knowledge infrastructures from first principles. The Ontology Pipeline™ emphasizes progressive context-building: moving from controlled vocabularies to taxonomies, thesauri, ontologies, and ultimately fully realized knowledge graphs.
Professionally, I have led semantic architecture initiatives at organizations including Adobe, where I architected an RDF-based knowledge graph to support Adobe’s Digital Experience ecosystem, and Amazon, where I worked in information architecture and taxonomy. I am also the founder of Contextually LLC, providing consulting and coaching services in ontology modelling, NLP integration, knowledge graphs and knowledge infrastructure design.

I am also a curriculum designer, teacher and founder of The Knowledge Graph Academy, a cohort-based educational program designed to train and up skill future semantic engineers and ontologists. The Academy is the the perfect balance of ontology and knowledge graph theory and practice, preparing graduates to confidently work as ontologist and semantic engineers.
An educator and thought leader, I publish regularly on my Substack newsletter, Intentional Arrangement, where my writing frequently explores the relationship between semantic systems and AI.
I think that Trump could say: "She's an incredible woman.... We like each other a lot and I think we'll find a deal... My administration has destroyed 80 % of our knowledge resources but we'll find a deal"
This presentation of the integration of knowledge, open communication, slack moral commitment to human progress is undermining knowledge based commons that open sharing forms the foundation.