

The Context Problem
Token Economics and the Word That Means Everything

Context, in information science, describes the relational structure that holds meaning in place. AI token economics has turned the concept of context into a billing unit. AI customers, in response, ran with the word context, and started applying context to every AI interaction. Marketing and venture capital companies invented an entire product landscape based upon context, positioning context as every company’s moat, the differentiator.
Meanwhile, foundation AI companies leveraged the context craze, pushing the onus of poor AI performance back on users, blame context quality for AI implementation failures and AI hallucinations . But context has not been defined in a meaningful way, except to say that the cost of using AI is associated with tokens and tokens are directly attached to context and context is what everyone needs to be successful with AI systems.
When commercial AI companies architected the token marketplace, context became the talking stick and the measuring stick, a convenient objective, tied to the outcome and key results. Yet there is little guidance from foundation AI companies, as to what constitutes context. Are we discussing context relative to tokens or context designed for AI reliability? Is it a graph? A markdown file? A YAML format or schema tables? Maybe it’s contextual understanding through a mixed methods approach?
For lack of clarity and agreed upon information architecture patterns, AI token economics has continued to soldier onwards, unchecked and rarely questioned. Secondary context marketplaces have emerged to meet market demand for context. Products, services, consultancies and sages have flooded marketplaces with context- oriented solutions, absent of any consensus as to the meaning and structure of context. And now that context is enmeshed with tokens, everyone wants context because context accounts for the majority of any organization’s AI spend. It’s a downward spiral, with no end in sight.
The Context Pricing Models
The pricing models of large language model APIs charge by the token. As the Technology Policy Institute explains, a token is the smallest unit of information an AI model processes—a snippet of text ranging from a single character to an entire common word—and all inference is metered against these units.1
IBM’s technical reference defines the context window in explicitly economic terms—the amount of text, in tokens, that a model can consider or “remember” at any one time, describing it as “the equivalent of its working memory.” 2 NVIDIA frames the exchange rate by noting that tokens are the currency of AI, and AI services increasingly structure pricing plans around a model’s rates of token input and output.3 Google’s Gemini API documentation states the transaction directly—billing is determined by the number of input and output tokens, with a token equivalent to roughly four characters of text—about 60 to 80 English words per 100 tokens.4
This is an intentional technical arrangement that has fiscal implications. It is also why context began doing more work than any single word should be asked to carry—functioning simultaneously as a noun (the context window), a verb (to contextualize a prompt), and an adjective (contextual AI). That grammatical sprawl has real financial consequences for those paying for it, and structural consequences for anyone trying to build systems that reliably reason.
Context as a Billing Unit
Context window capacity is the primary axis on which frontier AI models are now priced and differentiated. The table below compares current pricing across major models. The spread encodes a market stance—larger context commands higher value, and the most capable reasoning earns a premium rate per token.
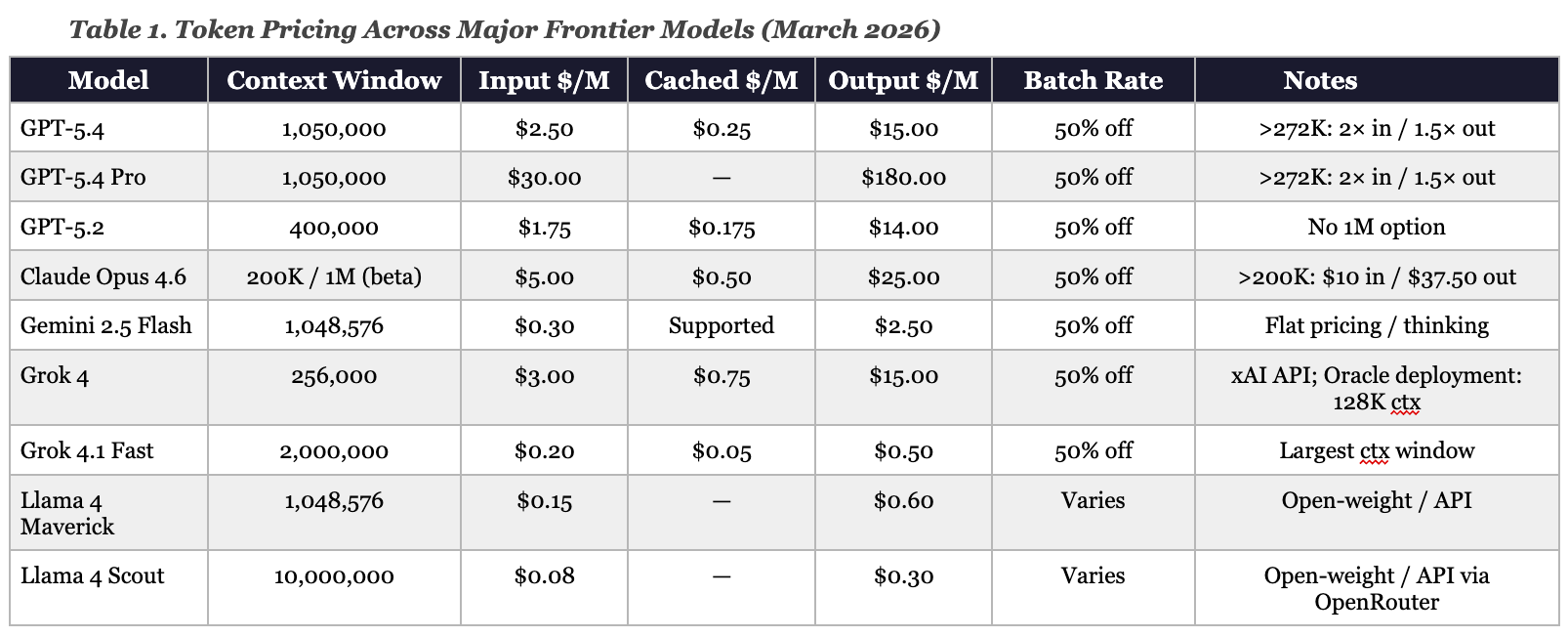
Notice how the range across this table is discontinuous. GPT-5.4 Pro output costs $180 per million tokens.5 Gemini 2.5 Flash output costs $2.50 per million tokens.6 That is a 72-fold difference in price for a unit that the market has defined using the word, context. Grok 4.1 Fast, xAI’s long-context model, supports a 2-million-token window at $0.20 input and $0.50 output—pricing that undercuts every comparable window size by a substantial margin.7 Llama 4 Maverick, Meta’s open-weight multimodal model, offers a 1-million-token context window at $0.15 input and $0.60 output via API providers, with the model itself available for self-hosting under a community license.8
